
In this article we are going to talk about machine learning operations, or MLOps, and how it can be used to make your machine learning practice more mature. Machine learning is an advanced and fast-moving space. However, for a field that is so much about technological advancement, it is often operated in a scarily primitive fashion. What do we mean by that?
“89% of machine learning and AI models don’t make it into production.”
And this is mostly because companies that venture into machine learning and AI don’t have in place a set of best practices that can help them make their machine learning transformation successful. If we look at machine learning development now, it is reminiscent of how software development was performed before the introduction of development operations.

Because after DevOps got introduced, software development allowed to transform itself, improve itself to allow for producing large-scale software systems.
Machine learning development at this moment is about to be transformed by a similar set of best practices called ML-Ops.
What is MLOps?
As described by Google, ML-Ops is a set of best practices to improve collaboration and communication between machine learning professionals and operations professionals. It aims to shorten and manage the complete development lifecycle and provide continuous delivery of high-quality predictive services.
How is machine learning operations exactly different from DevOps?
Although, machine learning operations stands on the foundations that DevOps already built, it differs from DevOps in the same areas where machine learning development differs from traditional software development.

- In machine learning development, data becomes part of your system. Through training, the data, in a sense, defines your deliverable. This is why, in machine learning operations, continuous integration is not only about testing your code, but also validating your data and its quality.
- Machine learning has a highly experimental nature. Dimensions within machine learning development are the tuning of your hyperparameters, selecting features, and almost every week new algorithm types come out. Often, it is hard to track how did we exactly get to our deliverable. And because of this, continuous delivery within machine learning operations is no longer about putting into production a single software package. It is about bringing forward a complete pipeline, one validated orchestrated experiment that then in turn can put a prediction service into production.
- Machine learning is subjective to ever evolving surroundings. Data changes constantly. Think about, for example, if you would make a shirt classification model. Fashion changes quickly. If your model was trained in a certain moment in time, but its surroundings are changing, the performance of your model will eventually decay. This is why in machine learning operations a new term is introduced called continuous training, which means that models are automatically retrained and monitored.
All of that sounds really promising, but how do we exactly apply this? What are the system requirements that we need to put in place to do this? Google has defined that really well in their maturity model, according to which you can assess the maturity of your machine learning operations practice. Let’s dive into that.
MLOps Level 0 – No Ops
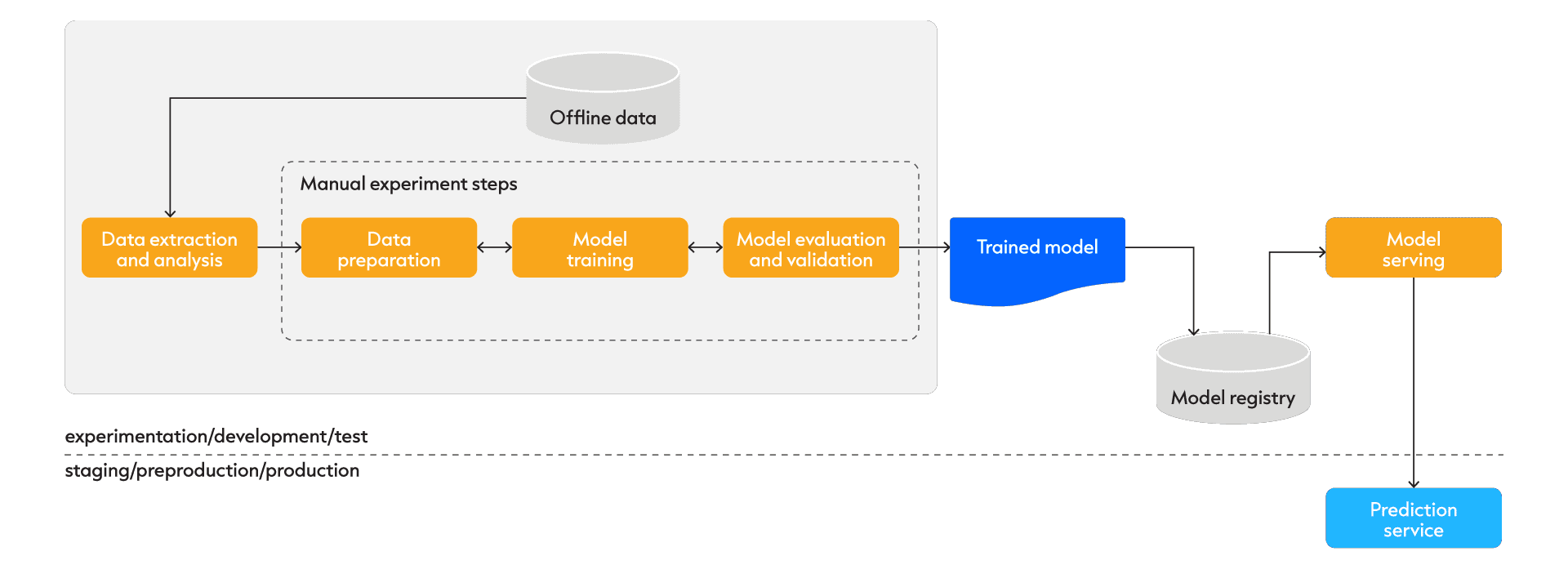
Machine Learning Operations Level 0 or NO-OPS has some characteristics along the following line. Mostly, the machine learning team uses some manually gathered static offline dataset and they have in place a series of scripts which they execute manually, and they also transition between the scripts manually.
The core of this level is a model registry, which is a repository used to store and version trained machine learning (ML) models. Model registries greatly simplify the task of tracking models as they move through the ML lifecycle, from training to production deployments. Additionally, a model registry stores information (metadata) about the data and the training process used to create the model. In the worst case, there is also not even a defined sequence or there are certain types of “magic functions” that they have to run in order for their model to work. All of this makes the process of training the model labor-intensive.
Secondly, it might be that the releases are infrequent. This can have multiple reasons. It could be because of the division between the machine learning team and the operations team, which makes collaboration between the two teams harder. Or it could be a type of chicken or the egg problem, which goes along the following lines:
- Because releases are infrequent, there is little incentive to automate the releases.
- And because the releases aren’t automated, they are manual and labor-intensive.
- And because they are manual, the releases become painful and hard to do,
- and because they are painful, the team doesn’t want to release frequently.
- And so on, and so on…
And when we go into production, we only deploy a prediction service, which results in an asymmetry between what we see in development and what we see in production. In development, we can actually train our model, but once we release our model into production, it cannot retrain itself. It is put in this ever-evolving surroundings and eventually we will see model decay.
And when this model performance decays, there is also no performance monitoring. There is no feedback loop to trigger a new cycle of training of our model. So, in the worst-case scenario, our feedback goes through the end user. The end user will see that the model performance is deteriorating. They will call up the project manager. The project manager calls up the data science team. And the problem is fixed after the fact. And that leaves everybody frustrated.
MLOps Level 1 – Automated Training

Machine Learning Operations Level 1 introduces automated training to solve these problems. And as we can see here, the steps that we first saw manually executed are now executed automatically one after another in one orchestrated experiment.
The core if this level is a feature store, which is a data system able to store and manage variables or features for ML/AI training and inference.
When we come to this experiment, when we have validated an experiment to work and being able to bring forward a properly trained model, we don’t bring that properly trained model into production, we deploy the complete pipeline. And this results in symmetry between development and production.
So, now we can actually retrain our pipeline in production continuously, bring forward newly trained models and deploy those models into our prediction service. It’s important to mention here that although these individual steps make one whole orchestrated experiment, it is vital to keep your code modular and reusable so that the team can experiment rapidly.
Secondary elements that need to be put in place in order for all this to work is a data validation step to make sure that only good quality data goes into our model. We need a feature store which automatically gathers data of which an offline extract can be taken to bring into development and start a new experiment or of which a batch can be fetched to bring into our automated pipeline in production to start retraining of our model.
Thirdly, monitoring and a pipeline trigger need to be put in place. So, when we see our model performance deteriorating, we want to trigger retraining of our model. Lastly, a machine learning metadata store and registry are put in place so that we can keep track of our previous models and their performance on certain datasets and features so that we can see if our performance is actually improving and if it’s not, we can roll back.
Even when all of this is put in place, there is still room for improvement. If your machine learning team is really catching the drift and start experimenting rapidly, this means that there will be many pipelines that need to be managed, many pipelines that need to be put into production. However, the machine learning team and the operations team, they are still divided. And we have no oversight of what the operations team is doing. There still might be some semi-manual deployment process, which can form a bottleneck in our whole machine learning operations lifecycle.
MLOps Level 2 – Full Automation
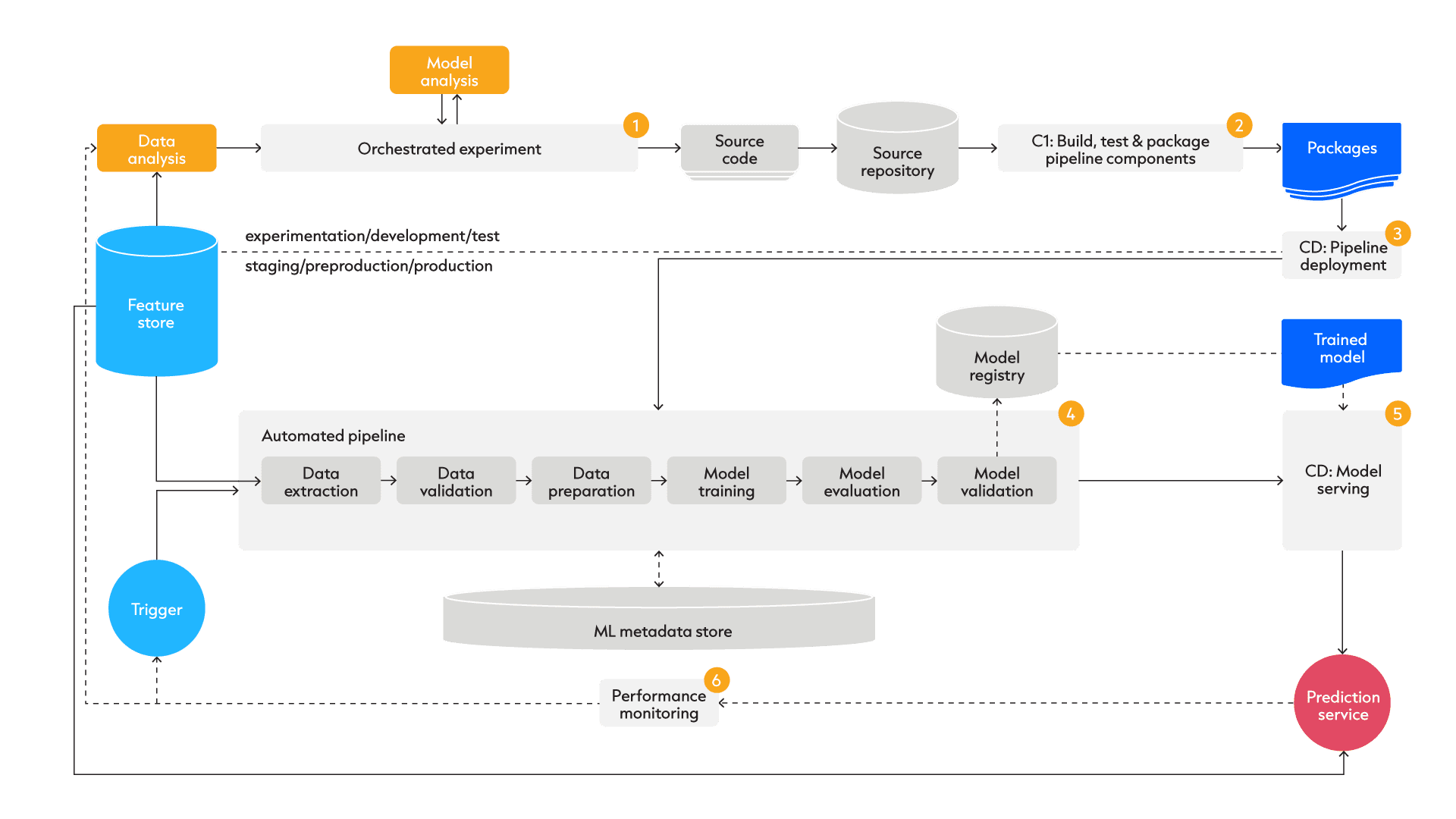
In MLOps level 2, we try to take away this bottleneck by introducing more automation in the deployment of our pipeline.
This is done by introducing continuous integration in building and testing and packaging our pipeline components but also introducing continuous deployment of our pipeline into production. So now we have two continuous deployment steps – one of our pipeline into production, and then of our trained model into our prediction service.
“And breaking down the barrier between machining operations is not as much a technical requirement, it is an organizational one. It needs to be decided top-down that there won’t be a separated machine learning team and operations team anymore.”
Everybody holds the responsibility for the complete machine learning operations life cycles, although everybody has their own role.
What is the takeway?
So, to summarize, in MLOps, machine learning and IT operations professionals work closely together to manage the lifecycle from experimentation code into automatically integrated machine and pipelines.
They do this by putting a large emphasis on data validation, automation, retraining and monitoring of the production metrics. This is done to keep our releases low friction, which allows for rapid experimentation and adaption to an ever evolving surroundings. And this is so that our systems can keep on delivering high quality predictive services while approaching zero downtime.
As a closing remark, we want to say that many companies want a slice of the machinery pie because it holds so much value. However, these companies are finding out that machine learning is hard by itself, but moving and staying into production is even harder.
And, Gartner identified having an experienced solution partner as the most important success factor for companies venturing into machine learning and AI.
This brings us to one of the solutions that Eraneos provides to its customers – the Data Hub. The Data Hub is a data platform that is architected completely according to the lines of these best practices in data and machine learning to ensure cost-effective, secure and scalable infrastructure.
And by design, it provides drag-and-drop development of machine learning pipelines, pipeline monitoring, model versioning and validation, and scalable data processing for all kinds of data. For example, we have used MLflow, which is open-source platform for the ML lifecycle that includes not only a robust model-registry but also experiment tracking. Additionally, it is able to deploy common ML frameworks (Scikit-learn, SparkML, XGBoost, LightGBM, TensorFlow, Pytorch, …) in the major cloud providers and Kubernetes.
If you are interested in this solution or want to learn more about MLOps, you can contact us here.
Stay up to date!
Are you enjoying this content? Sign up for our (Dutch) Newsletter to get highlighted insights written by our experts.




