In the world of analytics tools, Azure Data Explorer (ADX) tends to fly under the radar, overshadowed by the buzz around products like Databricks, Fabric, and Snowflake. However, don’t let ADX’s low profile fool you—it’s a powerful, reliable, and mature analytics solution, especially geared towards handling log and metric data.
Think of ADX as your go-to ‘timeseries warehouse.’ It’s built to smoothly handle continuous data ingestion, offer operational insights, and support analytics. Notably, it plays a crucial role in Azure’s Monitoring stack. Whenever you’re diving into metrics or querying logs, you’re tapping into ADX, showcasing its scalability and maturity.
This article provides an introduction into Azure Data Explorer and explains why I consider it a gem within Azure (maybe even worldwide…). It will be concluded with some best practices based on extensive work with ADX. I plan to follow up with more in depth articles on modelling, testing and deployment but let’s first get started with the basics.
The fundamentals: ADX storage architecture
One of Data Explorer’s most important attributes is its speed, both the amount of data it can load as well as its query performance. The secret lies in its storage architecture, a crucial aspect that deserves a closer look.
ADX operates on an append-only paradigm, simplifying the engine and its storage structure. At its core, ADX functions as a (micro) batch engine, where ingested data is batched, stored in files known as ‘extents,’ and indexed. Batching occurs based on time or input size, resulting in small extents that are later merged into more efficient, larger ones by background processes. Ingestions and extents are treated as independent entities which allows for horizontal scaling.
Extents use a columnar storage format, storing and compressing column values together. This format significantly reduces data size, typically by a factor of 7, compared to the ingested volume. ADX allows extents to be partitioned and sorted on specific columns, further optimizing storage and boosting query performance. Coming from a Spark background myself I find it is very similar to Parquet and ORC files but with the major difference that extents have indexes. By default, everything including nested data (dynamic data type) and text is indexed. Strings are split and indexed using an inverted index allowing rapid text search and matching. These extent level indexes make queries very scalable and incredibly fasts. The image below depicts the simplified layout of a single extent. It consists of metadata like tags and creation time, column indexes which depend on the datatype of the column and the actual data stored per column in compressed blocks each containing 10K values or so. The index is used to find the bocks (if any) to read and extract to answer the query. This is also true for nested data and text as those are indexed as well.

All extents are stored in Storage Accounts which are part of the ADX service; i.e. users don’t see them. Hot data, identified by age and configurable per table, resides on SSDs for quick access. ADX operates as a clustered technology, with each node holding a subset of hot data on its SSDs. When new nodes are added because of scaling it writes the data needed from the underlying storage to its SSD’s so it can server queries. Because of this process ADX scale out can be rather slow as a node may have to load TB’s worth of data to its local SSD. Cold data can still be queried but with significantly reduced performance. Tables can be configured with a retention after which data is removed from cold storage as well and thus no longer available.
Everything combined leads to its impressive query performance:
- Indexes allow ADX to quickly determine which parts of which files it needs to answer a query.
- Only required columns, which are highly compressed, are read which minimizes the number of bytes the engine needs to read.
- Query load is shared across nodes in the cluster which get the data from local SSD’s (assuming only hot data is required).
The most important concepts regarding data (extents), separation of compute and hot/cold data tiering are shown below. It also depicts more advanced capabilities like cross cluster querying and follower databases described later.
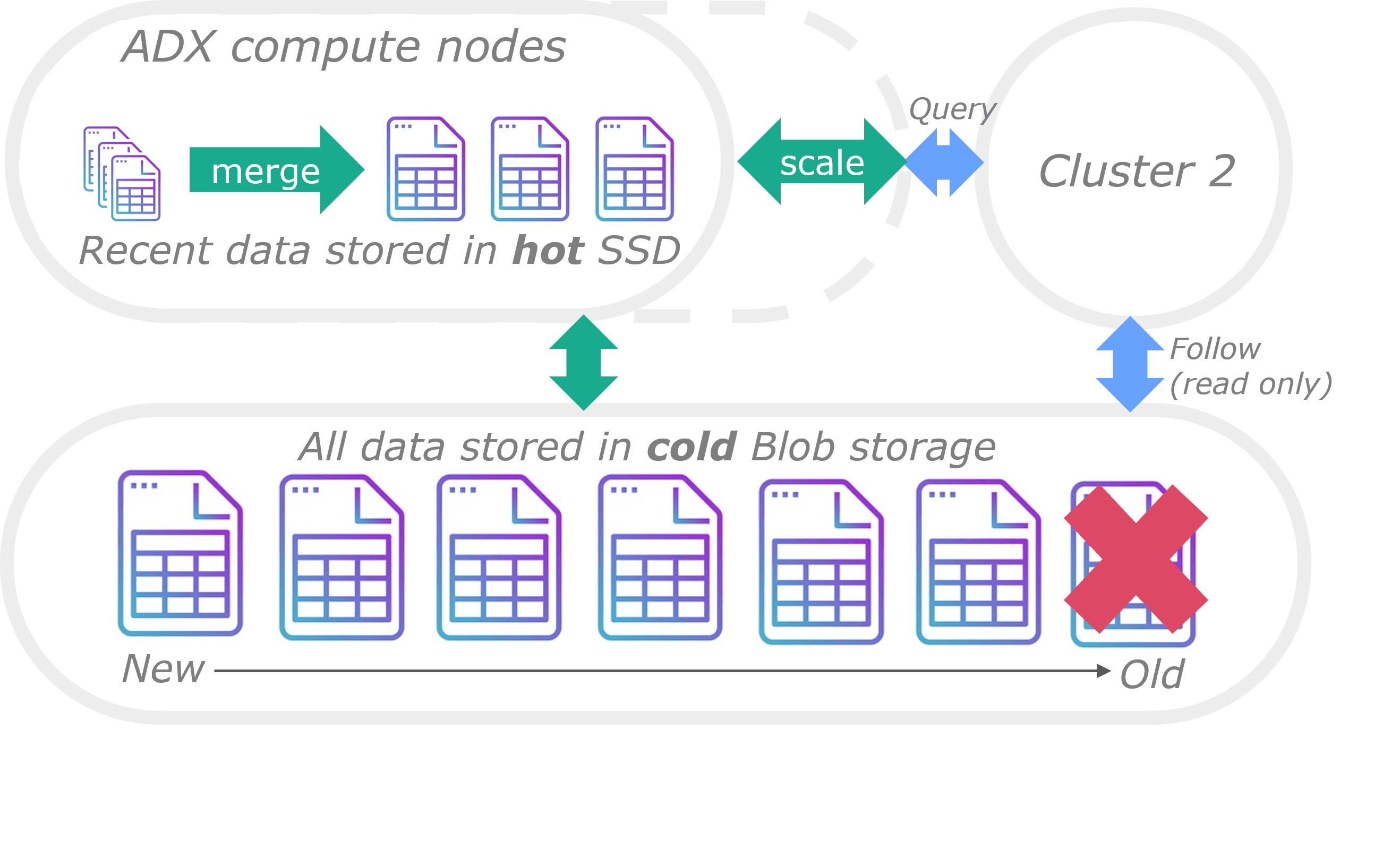
The above provides a brief and over-simplified overview of the ADX engine and its storage architecture. For more in-depth information please visit one of the following sources: Azure Data Explorer 101 or this Azure Whitepaper published by Microsoft.
Efficiency is key
What sets Azure Data Explorer apart is its distinctive storage architecture, a departure from the norm observed in many timeseries, log, and metrics solutions. While these often favor row-oriented (OLTP) storage, ADX takes a different route by embracing columnar storage. This choice introduces a balance between query speed and resource utilization, making ADX particularly efficient.
In the realm of row-oriented storage, solutions like Elasticsearch and Cosmos DB shine when fetching small numbers of records swiftly, achieving single digit millisecond query times. However, this efficiency comes at a cost—increased storage and memory consumption. For log and metric data, which can accumulate rapidly to vast volumes, this poses challenges.
Microsoft’s approach with ADX reflects a conscientious effort to optimize efficiency while maintaining a delicate balance between performance and resource utilization. This optimization is crucial, considering ADX’s role as the backbone for all Azure monitoring. As described in the whitepaper, Azure monitoring involved a staggering 210 petabytes of data, with a daily ingestion rate of 6 petabytes and a monthly query count reaching 10 billion. This is over five years ago, imagine what these numbers would look like right now… When it comes to ‘eating your own dogfood’ it does not get more real than this and Microsoft will be the first to notice when they introduce bugs or when efficiency starts dropping. In essence, ADX’s storage architecture stands as a testament to Microsoft’s dedication to providing a high-performance analytics solution capable of handling immense data volumes without compromising on efficiency.
The pricing consists of an ADX markup of 76 Euro per core per month and VM costs around 65 Euro per core per month (depending on VM family). Just for comparison this is roughly the same as Databricks premium DBU’s. Given the fact that ADX tends to be on all the time it makes sense to use ‘reserved instances’ to lower the overall costs by 40% for a 3-year commitment.
The fact that ADX does not provide the flexibility to easily terminate and spin up additional clusters like Databricks and Snowflake can be seen as a disadvantage. But in my experience ADX is setup a lot more like a ‘Clustered RDBMS’ allowing for a lot of concurrent operations to be executed which makes it more efficient. In contrast to other cloud data solutions that segregate jobs and queries using dedicated clusters, potentially leading to poor resource utilization, ADX embraces a more concurrent approach.
ADX’s capability to ingest multiple streams within a single cluster and execute queries simultaneously is a significant advantage. Although this approach may result in congestion, it can be mitigated, albeit not entirely, by scaling out reactively or proactively. While some may perceive ADX as relatively expensive, it undeniably delivers substantial value for the investment, providing a robust and efficient platform for handling diverse workloads at very impressive speeds.
Icing on the cake: ADX features
Besides its impressive query speed ADX provides a lot of features making it a very flexible tool. These include:
- Its own query language KQL (Kusto Query Language) which I find very powerful and user friendly. It is more flexible than SQL and avoids typical sub-queries required within SQL. The consensus is that it is a great and powerful language worth learning. It should be noted that ADX supports SQL as well and can be accessed using standard SQL server drivers which makes it easy to integrate with. KQL really increases ADX’s usability allowing less technical people to work with it and create dashboards. It is the same language used my Azure Log Analytics so worthwhile learning when working with Azure. Every year the ADX team creates new ‘Kusto Detective Agency’ challenges which offer a fun way to learn KQL on a free cluster.
- Unstructured and semi-structured data are a first-class citizen in ADX. Unstructured text like log lines can be parsed by various powerful ways into typed columns. A line like ‘2023-10-15T13:45:65.1473 : INFO – Received 561 messages’ can be parsed into timestamp, loglevel and message using ‘parse line with * timestamp:datetime ” : ” errorLevel:string ” – ” message:string’. As stated before, all text is indexed so even when data is not parsed it can be searched using statements like ‘where line has ‘error’’. JSON and XML can be parsed into nested structures which can be transformed (flattened, exploded, restructured, etc.) further. These structures are indexed as well so can be filtered, searched and aggregated on. There are some pro’s and cons regarding nested structures and their larger storage consumption which I plan to write another article for.
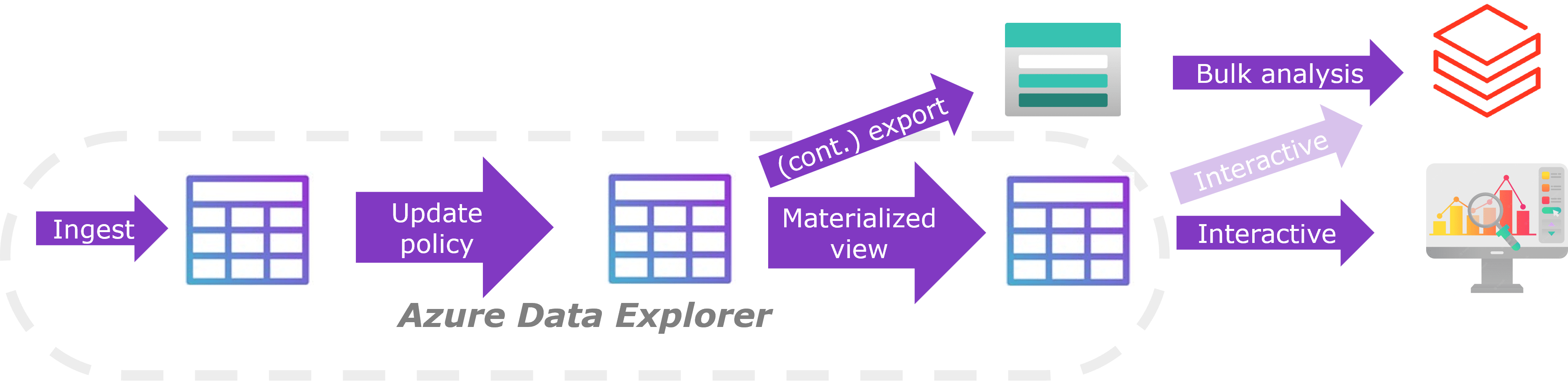
- Data mappings, update policies, materialized views and continuous exports allow new records from source tables to be parsed, transformed, joined, loaded to target tables and even ‘synced’ to an external SQL DB or Data lake. This includes options to parse semi & unstructured data (XML, JSON, CSV and text) but also joins with other tables. Joining streams with each other or with reference data is typically a hard scenario but can be done rather efficiently in ADX from local SSD’s. It is possible to split complex transformation into smaller pieces by writing and reading tables which are not persisted. These only exist in memory and simply acts as a ‘stream’ between transformations. No external ETL/ELT ‘tooling’ is required although for big transformation jobs it might be more performant to use a scalable external ‘ETL’ solution like Databricks to do the heavy lifting. The diagram below shows a simple flow in which data is ingested, parsed using an update policy, continuously written to a data lake (for bulk analysis using Databricks o.i.d.), continuously aggregated using materialized views and analyzed using a tool like Azure Data Studio.
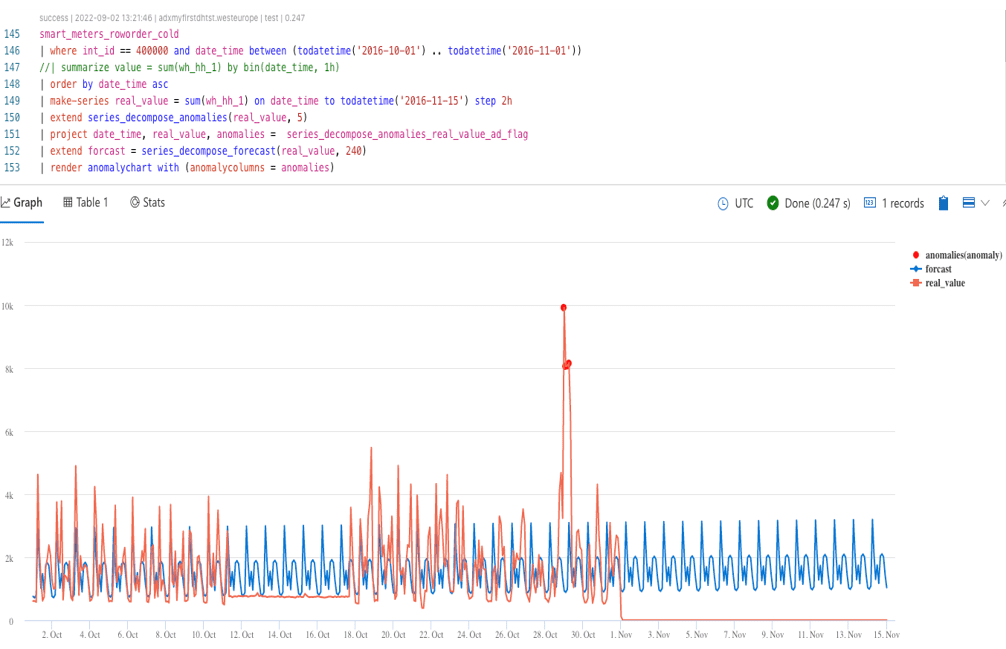
- A number of analytical functions such as timeseries functions, graph analysis, geospatial functions and process mining. These are very convenient to perform basic analytics with relative ease. When this is insufficient it is also possible to execute Python or R running in sandboxes on cluster nodes using data frame as input and output. This allows for more complex data manipulation, for example ML inference. For timeseries ADX supports functions like datetime aggregation, line fitting (regression), seasonality detection, missing values filing, anomaly detection and forecasting. Although not commonly used they can come in handy as I have noticed within my projects. The screenshot below shows the query and chart to perform forecasting and outlier detection for a series containing household energy consumption. As shown ADX is able to detect a daily pattern and perform forecasting and anomaly detection based on that. It definitely is not state of the art but can still provide a simple way to provide users with some additional insights.
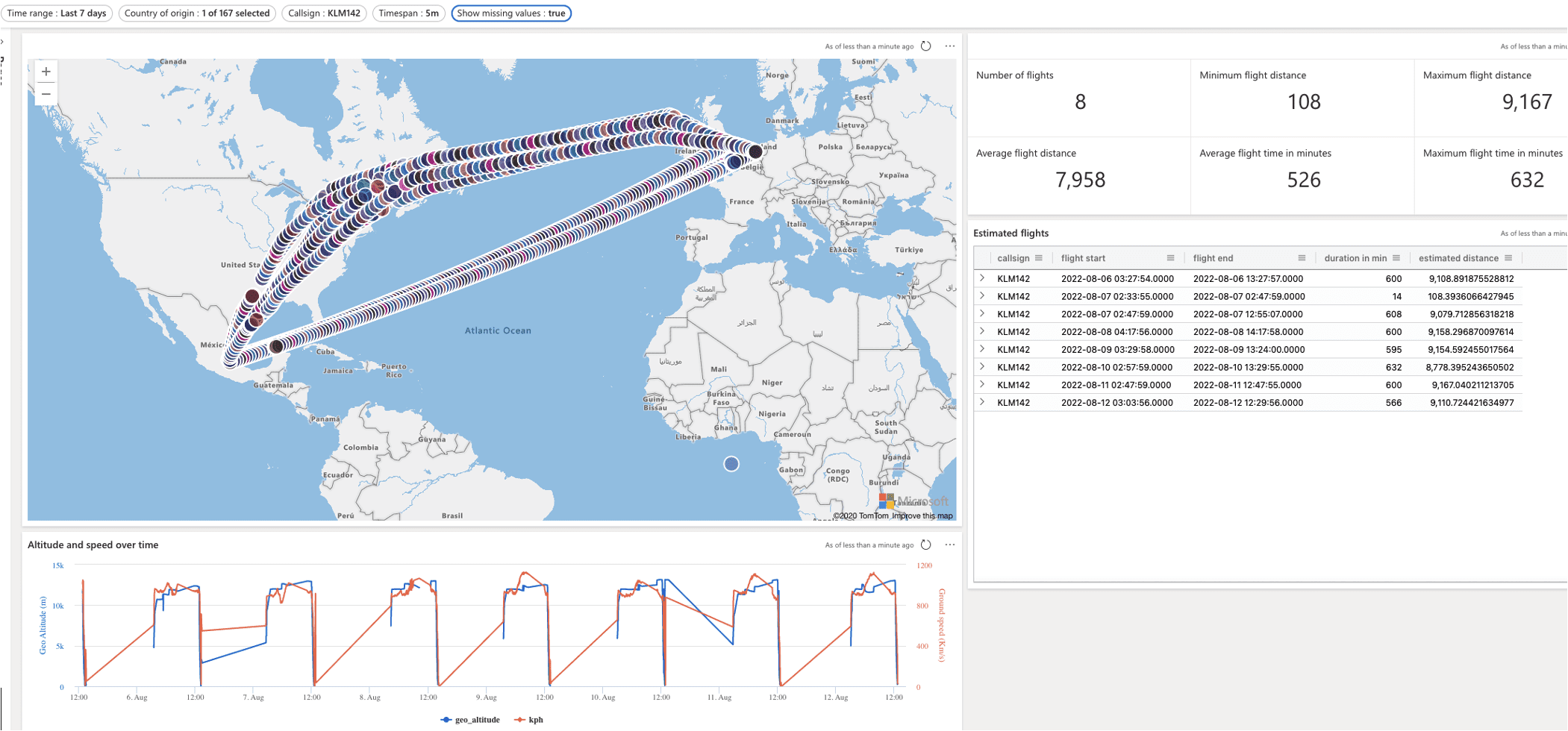
- A Dashboarding function allowing data to be visualized in various ways and exposed to others. It is by no means a substitute for something like Power BI but does provide an easy way to expose data and insights to (business) users. Grafana can also be used to provide a richer dashboarding experience. Screenshot below shows a simple dashboard showing airplane information (location, altitude, etc.) from the OpenSky network. Microsoft has clearly prioritized function over form as there are hardly any options to make dashboards pretty. Nevertheless they are very suitable for quick PoC’s and self-service purposes.
- External tables allowing data stored in SQL DB, MySQL, PostgreSQL, Cosmos DB and Data Lakes to be combined with data in ADX. These storage solutions can be queried directly using KQL without the need to move that data. In this way master data can reside in a relational database which can be combined with metric data stored in ADX on query time. In essence ADX supports a lightweight form of data virtualization. It must be noted that the use of external tables negatively impact query performance as data will have to be queried from a remote database.
- Azure Data Explorer supports both manual and automatic ways to scale vertically and horizontally. The automatic scaling can be reactive and even predictive based on load patterns using the timeseries capabilities just mentioned. It must be noted that scaling out is rather slow as data must be loaded from cold storage onto the SSD’s which takes time and I have seen it taking over 30 minutes. In addition, ADX supports cross cluster queries and option to follow a database. This last feature enables separation between workloads as one cluster can be responsible for data ingestion while a separate cluster with a follower database handles query load. This would be similar as having a Spark cluster performing streaming ingestion and another (SQL Warehouse) executing queries on the data.
- Provides a REST API as well as a SQL Server database connection which makes it very easy and flexible to integrate with. A lot of data solutions including Excel, Power BI, Databricks, Data Factory and Stream Analytics support ADX natively. Because it supports a database connection anything with a SQL Server ODBC/JDBC option can access it. Because of this ADX can even be used as a linked server from SQL Server opening up the possibility to store metrics in ADX and maintain metadata in a (light weight) SQL Server
It is too good to be true
While Azure Data Explorer excels in many aspects, there are some drawbacks worth considering. One notable limitation is its optimization for micro-batch processing, making it less performant in scenarios involving bulk data processing. Loading substantial amounts of data, especially for historical or full load Extract, Load, Transform (ELT) paradigms, can be time-consuming and prone to failures.
Ingestions in ADX predominantly rely on a single core with a fixed timeout of 60 minutes. Although multiple ingestions can run in parallel, it necessitates manual management or the use of tools like Data Factory or Synapse pipelines for orchestration. The recommended approach involves splitting large jobs into smaller parts, such as loading a historic dataset per day or month, to enhance manageability. While parallel loading is possible, the complexity of manual management or the reliance on additional orchestration tools makes it hard.
Comparatively, Databricks Spark offers a simpler approach to handling massive datasets. Its ease of ‘ETL’ing a substantial dataset as a whole or in sizable pieces, with less concerns about memory or timeout limitations, makes it a more straightforward solution for scenarios involving the heavy lifting of large data volumes. In fact, using Databricks for loading a significant amount of data into ADX allows Databricks to handle the bulk of the workload, while ADX efficiently writes the data in small batches. This collaborative approach mitigates some of the challenges associated with ADX’s micro-batch processing limitations.
Another significant constraint is the inability to update records directly. Managing updates in ADX involves appending fully updated records and then handling the removal or filtering of ‘old’ records when querying data. This approach can be streamlined using (materialized) views that leverage arg_max() or arg_min() aggregations to retrieve the latest state based on a (multi-column) identifier and timestamp.
An alternative method involves overwriting a dataset entirely through a set-or-replace type of operation. However, this approach can be resource-intensive. Although it is possible to work around the ‘no update’ limitation within ADX, the process is somewhat cumbersome. Ideally, such operations should be conducted outside of ADX, utilizing SQL or Spark environments.
This limitation on direct record updates is a crucial factor to consider, especially when contemplating ADX as a generic data platform. While ADX excels in specific use cases, its constraints in data architecture and resource management may pose challenges for generic multi-team usage. As a result, I often advise against relying solely on ADX for generic data platform needs. The platform’s lack of flexibility in these aspects may make alternatives like Databricks or Fabric more suitable, especially for larger or more complex setups. These alternatives provide a more versatile and accommodating environment for a broad range of use cases and team dynamics.
Reference architectures & best practices
Microsoft provides tons of very high-level reference architectures on basically all topics, including ADX. Although valuable for inspiration on the high-level data flow and services used it provides very little information otherwise. This section aims to provide some of my own high level best practices using ADX and some services around it. There are a lot more details like modelling approaches, testing and deploying for which I intend to write separate articles.
The following provides a generic design and some best practices based on my experience from the last few years. It is abstracted away from actual use-cases and focuses on common patterns regarding ADX.
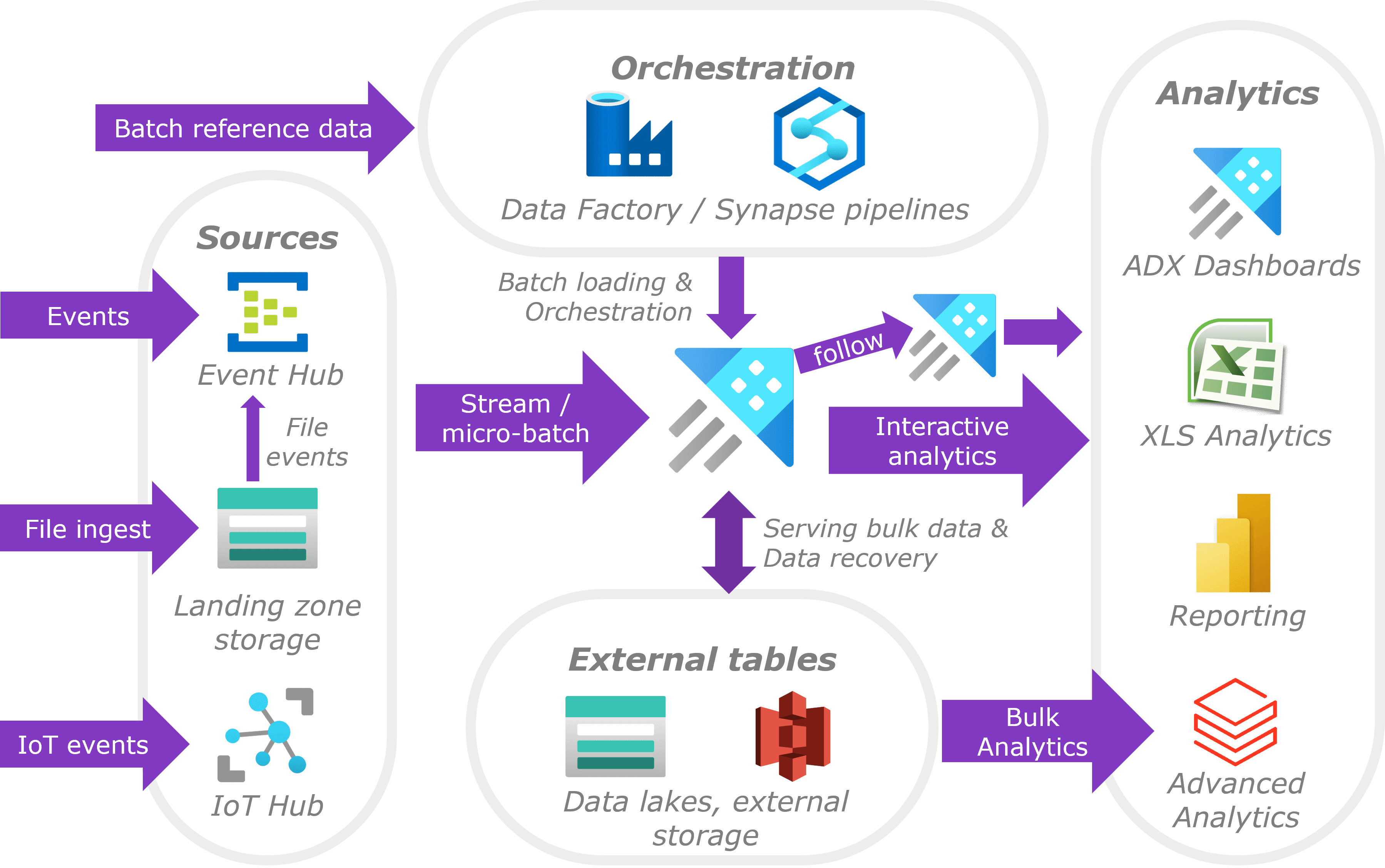
No matter the exact use case you are very likely to end up with a design such as this:
- From a technical perspective the primary sources will be IoT/Event Hub, CosmosDB and Storage accounts which ADX will ingest into staging/bronze layer tables automatically. Even when a data stream is presented as files ADX will still use an Event Hub to capture file creation events and manage its ingestion based on that. Event Hub with extended retention (up to 7 days) makes the setup very resilient and able to handle ADX downtime without any effort. Even when writing events directly from an application into ADX it may be worthwhile using an Event Hub for this purpose.
- External tables are often neglected but can have several benefits at the cost of data duplication. Within a common pattern the streaming data is parsed and curated within ADX and the result exported continuously as parquet to a ‘data lake’ as bronze or silver dataset (using a medallion data architecture). The data lake is used for bulk processing, for example Databricks or Synapse reading billions of records for advanced analytics purposes. ADX is suitable for interactive analytics returning datasets up to millions of records but providing data in bulk is slow and resource intensive and can better be handled by a data lake. An additional benefit of storing curated data is the ability to reload data from there to recover from an incident without the need to re-process source data. ADX provides some recovery methods as well, but these are not always easy to use. Other uses of external tables are:
- Using an (continuous) export is a generic way of serving data to interested parties both within the organization or outside of it. This avoids exposing ADX itself and allow consumers to work with the data as they see fit. An export is based on a query which allows the result to be customized specifically for the intended consumer. Data can be exported to Azure storage as well as S3
- External tables can also be used to load data prepared by other solutions like Databricks or Synapse. For example maintaining big slowly changing dimension tables using Databricks which are loaded into ADX to be combined with metric fact tables. ADX has been known to act as a serving/cache layer on a data lakes providing always-on query endpoint allowing very fast query response times. With the rise of Serverless endpoints I feel this pattern becomes less relevant but want to mention it none the less
- Data Factory or Synapse pipelines are often used for loading of reference data and orchestration. Although stream ingestion is the most natural way to load data into ADX there is often the need to load reference / master data as well. These are typically daily bulk loads which can be performed by ADF or Synapse pipelines. In addition, there tend to be other periodic tasks that need to be orchestrated like the afore mentioned exports, bulk transformations, data cleanup and cluster start/stop. The latter can be done from a pipeline accessing Azures management API and saves money by stopping unused clusters (typically dev / test ones). Even if those clusters have continuous ingestion they can be stopped because ingestion simply continues after startup (assuming an Event Hub is used).
- Given its interactive analytics nature Azure Data Explorer is mostly consumed by applications, dashboarding and/or analytics solutions like Power BI, Grafana, Databricks and the like. ADX’s dashboard functionality can be used to provide self-service capabilities (for data savvy people) and quickly deliver PoC’s before full blown dashboard development. Data lakes with parquet datasets and follower ADX clusters can be used to segregate data usage types and avoid conflicts. A ‘sometimes on’ analytics cluster with increased Hot storage can follow a small always-on cluster solely responsible for ingestion.
ADX can also be used as a generic batch oriented data platforms as described by ‘Building a Lakehouse using ADX’ or as ‘SSD cache’ on top of a data lake. This made somewhat sense a couple of years ago before the rise of Serverless SQL, Databricks Photon engine and Delta caching. I have actually implemented a very small ADX cluster as SSD cache on top of a data lake once to provide users a cheap, always-on and fast query experience. From a functional perspective it works very well, and users were very happy with it. But it does add quite some technical complexity and data duplication I would normally try to avoid. Now I would prefer (serverless) SQL endpoints and Databricks dashboards for visualization.
To conclude
Azure Data Explorer is a very mature, fast, efficient and feature rich solution. The fact that it is used for all Azure monitoring provides a high level of trust. Personal experiences, along with positive feedback from fellow data professionals, underscore ADX’s prowess, particularly in (operational) analytics on timeseries data. Its design and feature set make it a compelling and sometime more cost-effective alternative for specific use-cases, potentially rivaling Databricks stream processing and Azure Stream Analytics.
While excelling in various scenarios, ADX may not be the optimal choice for every situation. Contexts demanding low latency or an event-driven workflow find better alignment with services like Event Hub, Functions, and CosmosDB. For such scenarios, an architecture featuring these services, complemented by ADX for historization (e.g., via CosmosDB’s change feed), proves more fitting.
Despite occasional promotion as a batch platform, caution is advised in categorizing ADX purely as such. Its foundational design revolves around micro-batch stream processing, making it less suitable for significant batch processes that may encounter errors and limitations.
This article provided an overview on Azure Data Explorer along with some architectural best practices of my own. When time permits, I want to follow up by some more in-depth content on data modelling and development cycle (development, testing, deploying). If you are new to ADX and KQL I really recommend the Kusto Detective Agency as it is an awesome way to get started!
Ps. Kusto is the old internal name of Azure Data Explorer, and it is still sometimes referred to by its old ‘moniker’.
Do you want to learn more about ADX? Check out our Data & AI solutions, or reach out to our team.