
Veel van de aandacht voor innovatie gaat tegenwoordig uit naar grote taalmodellen en generatieve AI, maar gespecialiseerde AI-technieken zijn snel en vaak stilletjes op de achtergrond verbeterd. Dit artikel belicht hoe vooruitgang op gebieden als computervisie en patroonherkenning een aanzienlijke, praktische impact heeft op verschillende sectoren. Vooral omdat de wereld veel meer visuele en zintuiglijke gegevens produceert dan tekst, heeft vooruitgang op deze gebieden een buitenproportioneel effect op hoe organisaties processen in de praktijk kunnen begrijpen, automatiseren en optimaliseren.
Onlangs hield het Data & AI-team van Eraneos zijn halfjaarlijkse Innovation Day, waar we de nieuwste tools en technieken verkennen. Een van de teams koos ervoor om te zoeken naar toepassingen in de praktijk met behulp van het nieuwste vooraf getrainde computervisie-model van Meta: DINOv3 This link opens in a new tab. Na verschillende use cases te hebben getest, bouwde het team een demo This link opens in a new tabdie laat zien dat gespecialiseerde AI nog steeds van enorme waarde is, vooral bij het snel en goedkoop uitvoeren van een verscheidenheid aan computervisietaken, zonder dat daarvoor grote hoeveelheden gelabelde data nodig zijn.
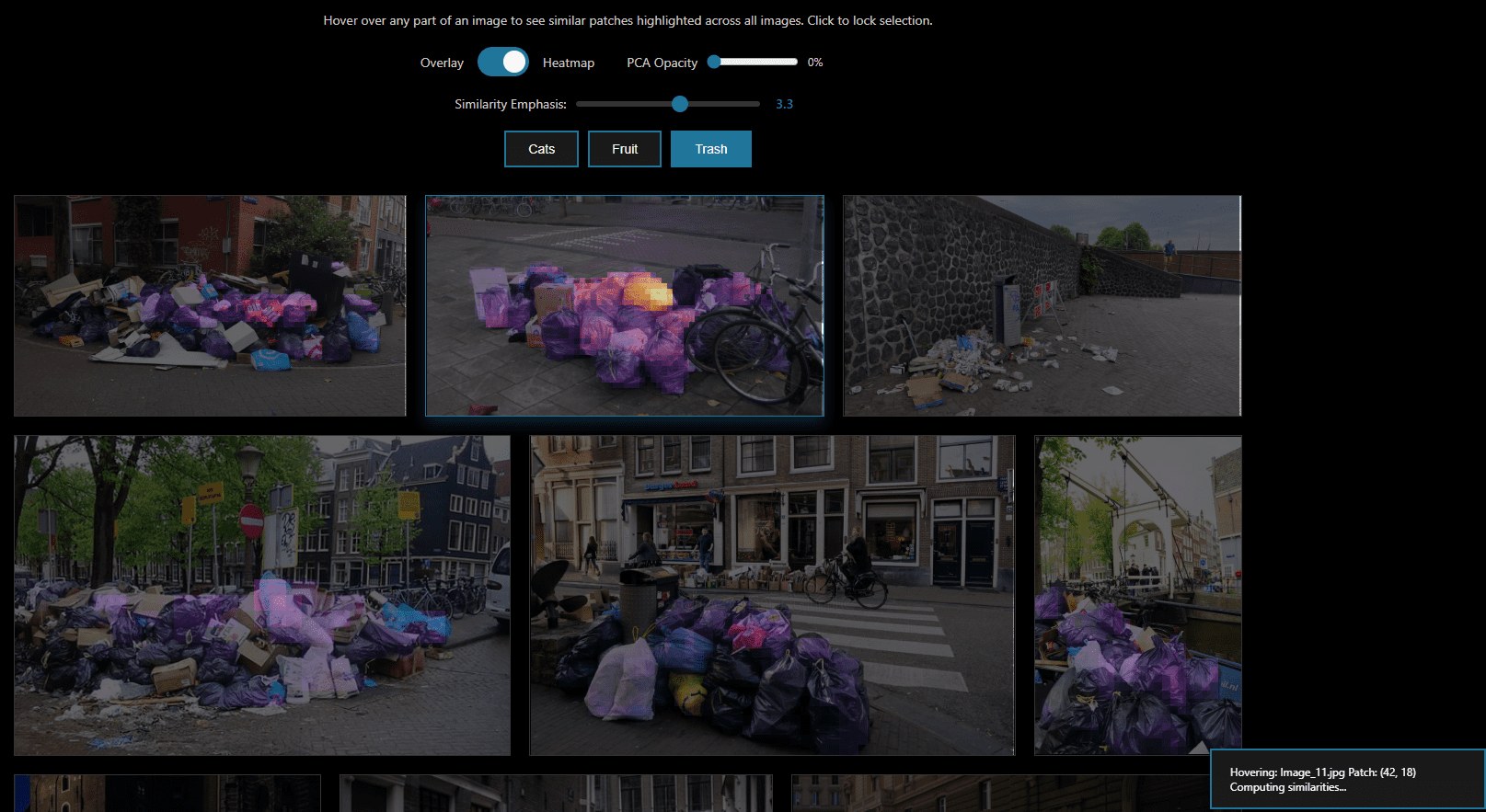
Image generated with the Eraneos DINOv3 Patch Similarity Viewer
Het projectteam, bestaande uit zowel datawetenschappers als software data-engineers, werkte samen om de mogelijkheden van het model en de beste toepassingen ervan op elkaar af te stemmen. We hebben de dag zo gestructureerd dat we niet alleen deze klassieke AI-technologie konden begrijpen, maar ook snel het potentieel ervan konden demonstreren aan de hand van meerdere use cases, gericht op een praktisch en herkenbaar onderwerp: afvaldetectie.
Motivatie
Het team voelde zich aangetrokken tot Dinov3 omdat het een speciaal computervisie-model is en geen standaard generatief model. In tegenstelling tot de meeste GenAI-modellen lost DINOv3 specifieke, real-world problemen op met een ongekende efficiëntie. De USP van het model ligt in de training: het is niet getraind met door mensen gelabelde data, maar met miljarden ongelabelde afbeeldingen. Dit zelfgestuurde leerproces maakt de resulterende beeldrepresentaties, ook wel vectorembeddings genoemd, ongelooflijk rijk en krachtig. Dit trainingsproces pakt de grootste bottleneck in traditionele computervisieprojecten aan: de tijd en kosten die nodig zijn om enorme datasets handmatig te labelen. Bovendien heeft het model kleinere versies die op edgeware en in realtime kunnen draaien, en kan het met minimale inspanning voor verschillende taken worden gebruikt, zoals we hieronder verder zullen aantonen.
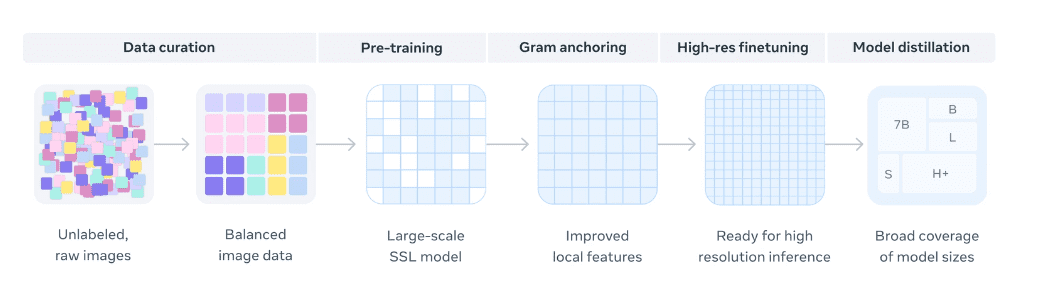
DINOv3 Data curation
Het Meta-team gebruikte een techniek waarbij het DINOv3-model werd getraind op een enorme, ongelabelde dataset van afbeeldingen om zelf de structuur en betekenis te achterhalen, vergelijkbaar met hoe een LLM de taalstructuur leert door het hele internet te lezen. Het DINOv3-model werkt op een fundamenteel andere manier dan andere AI-modellen, waaronder Meta’s Segment Anything Model (SAM), dat weliswaar geavanceerd is, maar nog steeds aanzienlijke labeling vereiste tijdens de trainingsfase. Door Dinov3 te gebruiken voor onze use cases, wilde het team aantonen dat geavanceerde computervisie nu gemakkelijk en goedkoop toegankelijk is voor vrijwel elke fysieke industrie.
Afvalbeheer heroverwegen
De publieke sector is nog steeds sterk afhankelijk van handmatige processen voor monitoring, inspectie en handhaving, met name op gebieden als afvalbeheer en onderhoud van de openbare ruimte. Het opsporen van illegaal storten, zwerfafval en gevaarlijk afval blijft arbeidsintensief en kostbaar voor gemeenten, maar leent zich uitstekend voor automatisering met behulp van moderne computervisie. Om deze reden hebben we tijdens de Innovation Day gekozen voor afvaldetectie als ons toepassingsgebied, voortbouwend op de eerdere ervaring van het team met gemeentelijke use cases.
De technische kern van ons werk was gebaseerd op de output van het DINOv3-model. Elk beeld wordt opgesplitst in patches van 16×16 pixels, waarbij het model voor elke patch een rijke vector-embedding genereert die zowel de semantische betekenis als de geometrische structuur vastlegt. Deze embeddings vormen de basis voor alle downstream-taken, zoals het zoeken naar overeenkomsten, classificatie, segmentatie en tracking.
In de loop van de dag hebben we vier verschillende toepassingen gebouwd en gedemonstreerd die de veelzijdigheid van deze aanpak illustreren.
Visuele semantische gelijkenis – Vindt alle vergelijkbare objecten in een dataset zonder finetuning
In een webdemo werden door het selecteren van een enkel fragment, bijvoorbeeld een stuk afval, onmiddellijk alle vergelijkbare objecten in de dataset opgehaald en gemarkeerd, waarmee zero-shot segmentatie werd gedemonstreerd.

Image generated with the DINOv3 Patch Similarity Viewer
Hierbij is het belangrijk op te merken dat de visuele semantische gelijkenisdetectie direct werkt zonder dat er finetuning, hertraining of wijziging van het bevroren model nodig is. Stel je voor dat je één object in een afbeelding kunt selecteren en direct alle vergelijkbare objecten in je hele afbeeldings- (of videodataset) kunt vinden, zonder tijdrovende en kapitaalintensieve label- en trainingscycli voor aangepaste visuele modellen.
De mogelijke toepassingen zijn eindeloos, maar we hebben een aantal toepassingen geschetst voor het vinden van alle vergelijkbare objecten in een dataset zonder finetuning:
- Voorraadbeheer in de detailhandel – Identificeer onmiddellijk alle exemplaren van een specifiek product in magazijnfoto’s voor voorraadtelling
- Detectie van dubbele meldingen – Vergelijk door burgers ingezonden afbeeldingen van problemen (kuilen, graffiti, afval) om dubbele meldingen voor gemeenten te identificeren
- Kwaliteitscontrole in de productie – Selecteer één keer een defecttype en markeer vervolgens automatisch alle vergelijkbare defecten in de beelden van de productielijn
- Productmatching voor e-commerce – Zoek dubbele of vergelijkbare vermeldingen in grote catalogi om fraude te voorkomen en het zoeken te verbeteren
- Monitoring van natuurbehoud – Identificeer alle exemplaren van een specifieke diersoort in cameravastgelegde beelden zonder soortspecifieke training
Video-objecttracking – Volgt een geselecteerd object in een video
In een ander voorbeeld werd het model gebruikt voor het volgen van objecten. Dit werkt als volgt: zodra een object in een enkel videoframe was geselecteerd, kon het betrouwbaar worden gevolgd gedurende de rest van de reeks.
Image generated with the DINOv3 Patch Similarity Viewer
Hier hebben we ook een aantal mogelijke toepassingen geschetst van het betrouwbaar volgen van een geselecteerd object gedurende een videosequentie:
- Logistiek en magazijnautomatisering – Pakketten, pallets of vorkheftrucks volgen via camera’s in de faciliteit om de doorstroming te optimaliseren en knelpunten op te sporen
- Sportanalyse – Volg individuele spelers of de bal tijdens een wedstrijd voor prestatieanalyse en tactische inzichten
- Verkeersmonitoring – Voertuigen volgen via kruispunten om verkeerspatronen te analyseren, overtredingen te detecteren of congestie te meten
- Analyse van het klanttraject in de detailhandel – volg winkelwagentjes of klanten door winkels om gedrag te begrijpen en lay-outs te optimaliseren
- Veiligheidsmonitoring op bouwplaatsen – Werknemers en apparatuur volgen om naleving van veiligheidszones en protocollen te waarborgen
Objectdetectie – Classificatie met een minimum aan gelabelde voorbeelden
We hebben ook een lichtgewicht classificatiemodel getraind met slechts ongeveer 20 voorbeelden om gevaarlijke objecten zoals lachgasflessen en gebroken glas te identificeren. Ondanks de minimale trainingsgegevens presteerde het model uitstekend met een nauwkeurigheid van 80% bij het detecteren van gebroken glas en 100% bij het detecteren van lachgasflessen. Dit onderstreept hoe krachtige embeddings een snelle modelontwikkeling mogelijk maken.
Met DINOv3 is het nu mogelijk om aangepaste objectdetectie uit te voeren met een orde van grootte minder gelabelde trainingsgegevens. Dit verlaagt de kosten aanzienlijk, waardoor veel toepassingen die voorheen te duur waren om te implementeren, nu haalbaar zijn geworden.
Enkele toepassingen van lichtgewicht classificatie met een minimum aan gelabelde voorbeelden (~20 monsters):
- Identificatie van gevaarlijk afval – Detecteer gevaarlijke voorwerpen zoals chemische containers, naalden of gasflessen in openbare ruimtes of afvalstromen
- Detectie van infrastructuurdefecten – Identificeer scheuren, corrosie of schade aan bruggen, wegen en gebouwen met een minimum aan trainingsafbeeldingen
- Opsporen van plagen en ziekten in de landbouw – Train snel op basis van enkele voorbeelden van gewasziekten of plaagschade voor vroege detectie
- Identificatie van namaakproducten – Detecteer namaakproducten of producten die niet aan de normen voldoen op assemblagelijnen of bij douanecontroles
- Naleving van veiligheidsvoorschriften – Controleer of werknemers de vereiste PBM’s (helmen, vesten, veiligheidsbrillen) dragen in industriële omgevingen
Segmentatie – Onbegeleide clustering in zinvolle categorieën
Ten slotte was het systeem door middel van onbegeleide clustering in staat om beeldfragmenten te groeperen in zinvolle categorieën zoals “afval”, “water” en “vegetatie” zonder vooraf gedefinieerde labels, waarmee het zijn vermogen om visuele gegevens automatisch te structureren aantoonde. Een mens hoeft een categorie slechts één keer te labelen om deze in de hele dataset herkenbaar te maken.

Image generated with the DINOv3 Patch Similarity Viewer
Enkele toepassingen van onbegeleide clustering in zinvolle categorieën:
- Landgebruik en stadsplanning – Automatisch categoriseren van satelliet- of luchtfoto’s in zones (vegetatie, water, gebouwen, wegen) zonder vooraf gedefinieerde labels
- Milieumonitoring – Segmenteer dronebeelden om gebieden te kwantificeren die zijn getroffen door overstromingen, ontbossing of vervuiling
- Triage van medische beelden – Groepeer weefselgebieden in pathologische dia’s of scans om gebieden te markeren die nader moeten worden onderzocht
- Analyse van landbouwvelden – Segmenteer gewasbeelden om onderscheid te maken tussen gezonde vegetatie, gestresste gebieden, onkruid en kale grond
- Autonoom voertuigscènebegrip – Categoriseer wegscènes in berijdbare oppervlakken, obstakels, voetgangers en bewegwijzering voor navigatiesystemen
Wat we hebben bereikt
In slechts één dag heeft ons team kunnen aantonen dat DINOv3 een tool is met een buitengewone reikwijdte. We hebben bevestigd dat het in staat is om hoogwaardige resultaten te leveren voor verschillende cruciale computervisietaken – identificatie, tellen, volgen en segmenteren – met minimale gegevens of handmatige invoer.
De toepassingen zijn zeer breed en strekken zich uit tot elke sector die gebruikmaakt van menselijke controle s of camera’s om de fysieke realiteit te beoordelen, van gemeentelijke afvalinzameling (het opsporen van dubbele meldingen door beelden te vergelijken) tot productie (kwaliteitscontrole en het volgen van onderdelen) en detailhandel (voorraadbeheer).
Misschien wel de belangrijkste prestatie is het bewijs van concept voor een totaaloplossing. De vectoroutput van DINOv3 kan naadloos worden geïntegreerd met onze bestaande oplossing voor gegevensdeduplicatie en -matching, Data Unity, die gebruikmaakt van bibliotheken zoals Splink. Waar we voorheen vectorembeddings afgeleid van tekst samen met gestructureerde gegevens toepasten voor entiteitsmatching, kunnen we deze aanpak nu ook uitbreiden naar visuele gegevens. Dit maakt het mogelijk om robuuste systemen te creëren die afbeeldingen, tekst en metadata tegelijkertijd vergelijken, waardoor de betrouwbaarheid van dubbele detectie en datakwaliteitsprocessen aanzienlijk wordt verbeterd. Door onze experimenten met DINOv3 hebben we aangetoond dat deze mogelijkheden nu sneller, kosteneffectiever en uitgebreider kunnen worden geleverd dan voorheen.
De weg vooruit
De resultaten van de Innovation Day laten duidelijk zien hoe ver computervisie de afgelopen jaren is gevorderd. De technologie kan nu visuele informatie snel, nauwkeurig en op grote schaal herkennen, classificeren en groeperen, waardoor de handmatige inspanning die nodig is om afbeeldingen te beoordelen en te interpreteren aanzienlijk wordt verminderd. Dit opent een breed scala aan praktische toepassingen in de publieke sector, de productie, de detailhandel, de verpakkingsindustrie en elk ander domein waar visuele gegevens een rol spelen.
Wilt u meer weten over de Eraneos DINOv3 Patch Similarity Viewer This link opens in a new tab die door ons team is ontwikkeld en de voordelen van het toepassen van deze technologie in uw bedrijfsvoering? Neem vandaag nog contact met ons op voor meer informatie.