
I still remember the moment I first heard the terms Bronze, Silver, and Gold. I was an architect at Bridgestone, discussing data layers, when a colleague mentioned a “new” architectural best practice from Microsoft. We adopted it, but it never quite sat right with me. It felt like a rebranding of concepts we had used for decades – names like raw, staging, transformed, and core – (also not brilliant) replaced by a suite of metals bronze, silver and gold.
While the Medallion Architecture This link opens in a new tab has since become an industry standard, I’ve witnessed countless counterproductive debates sparked by its terminology. I’m certainly not the first to feel this way; the Advancing Analytics video, “Behind the Hype – Medallion Architecture Doesn’t Work This link opens in a new tab,” deeply resonated with me. As is true with most of Simon’s content – do watch if you have never done so!
Seeking clarity, I turned to Piethein Strengholt’s Building Medallion Architectures This link opens in a new tab. The opening lines struck a chord: “Medallion architectures – I have a love/hate relationship with them. How could something so bluntly simple cause so much confusion…?” While the book brilliantly outlines the complexity of data layers and the separation of concerns, the “metal” naming convention still felt like an awkward fit. Most examples in the book describe sub-layers, which feels like a symptom of a naming system being stretched to its limits.
After watching architectural discussions drag on for months in a recent project, I realized the names themselves and ‘three layer restriction’ might be at the heart of the problem. I decided to pivot to a more descriptive approach. While my initial input was only a partial success, I’ve refined these naming guidelines and believe it’s time to share them hoping it will do some ‘good’.
The problem
From my experience the Bronze, Silver, Gold convention suffers from three major issues:
- It is restrictive: In practice, teams often find three layers insufficient, leading to awkward additions like “Tin,” “Diamond,” or “Platinum.” Alternatively, complex logical layers are sometimes forced into sub-layers just to maintain the Medallion aesthetic. This does not contribute to clear data architectures which is in the end what we aim to do. In addition it makes it hard to extend and I wonder how Semantic Layers fit into the picture
- It is non-descriptive: In IT, descriptive naming is a best practice. Medallion architecture deviates from this with the result that there are many different medallion architectures out there. This can also lead to time-consuming debates where certain responsibilities or transformations should belong. Because “Silver” is an ill-defined middle ground, it often becomes a “catch-all” for various transformations, muddying its purpose. At the same time I feel gold is over simplified and always ends up having more (sub)layers, for example a non-aggregated and aggregated one
- It over-simplifies design: The simplicity can trick people into believing that choosing “Medallion” replaces the need for proper design work. I have seen various “Medallion” implementations that were total messes because the naming convention was followed without defining actual responsibilities. Or putting tons of transformations within a single layer making them hard to understand and maintain
For me the medallion architecture really feels like something a marketing team came up with to ‘sell’ something complex but is holding us back in the actual implementation of it.
Descriptive naming guideline
Instead of a rigid convention, I propose a Descriptive Guideline that focuses on clarity and flexibility. In this guideline a layer name should consist of three components:
- Alignment (Required): Indicates how the data is modelled – typically source or business aligned (modelled for end-users). When a data architecture is ‘split’ across domains it can be supplemented by a domain indicator like ‘HR Source …’ or ‘Finance Business …’.
- Purpose (Required): Describes the purpose of the layer and is a small indication what consumers can expect from it, for example:
- ‘Stage’ to indicate it only holds data temporary
- ‘History’ indicating it contains ‘long term’ history
- ‘Access’ to indicate the layer is intended to facilitate data access in some way. It may contain (dynamic) views for example
- ‘Semantics’ to indicate a layer has reusable logic, for example a Semantic layer
- ‘Products’ telling users it contains business facing datasets, often data marts.
- Descriptors (Optional): a prefix to facilitate additional context like Clean, Harmonized, Integrated or domain name. These are useful for additional clarification but can easily be misused to create overly verbose layer names such as ‘harmonized integrated cleaned and validated hr business history’.
Using these guidelines, a data architecture might contain the layers depicted in the diagram (with explanation below). It is primarily intended to clarify the guideline but does contain layers I commonly encounter.
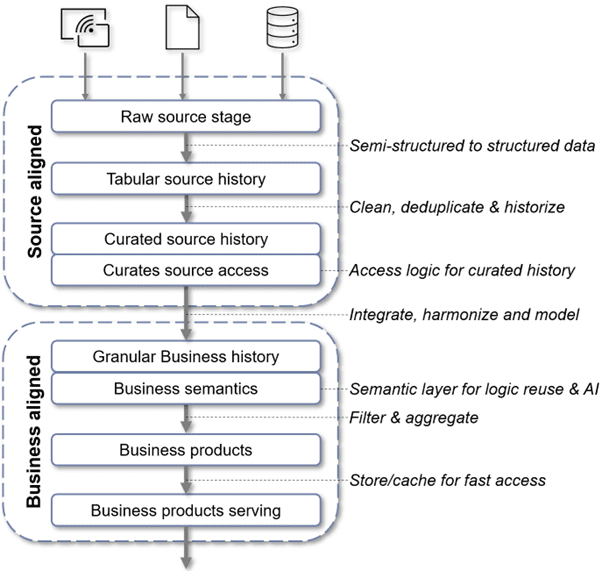
- Raw source stage: a temporary location, often cloud storage, to receive data from source systems. It is obviously source aligned and contains raw data (json, csv, etc.). Its main purpose is to ingest data into subsequent layer(s). If the raw data would be stored here long term I would change its purpose from ‘stage’ to ‘history’. Currently we would often call this a Landing Zone.
- It could be possible to have both a Raw source stage and Raw source history layer in which the history would keep data for long term. Sensitive data like PII could go in the Stage layer as it really is not desirable to keep that in raw form for long. Other data could still go into the History for auditing / archival purposes. For me it is totally fine to have layers next to each other with (slightly) different characteristics.
- Tabular source history: Stores source data in a tabular (structured) format; optionally including schema changes and duplicates. The data is source aligned and stored for long term as indicated by the ‘history’ suffix. Any transformations should be ‘incremental’ in the sense that columns could be added but original columns are not changed. This is similar to bronze in the medallion architecture and can be used to fully reload all downstream layers. In literature this layer is often described as immutable but for compliance reasons this is not always true; it may be required to remove sensitive / PII data.
- Curated source history: May contain deduplicated, possibly flattened, and historized (SCD1/SCD2) source data. It is source-aligned but refined enough for Data Science and advanced analytics. Curated is a subjective term but does indicate it has higher quality than ‘tabular source history’. In my experience such a layer often closely resembles the source structure but it is also possible to ‘model’ the data into a Raw (Data) Vault.
- Curated source access: A specific layer to manage data access and may consist of (dynamic) views and/or have specific logic for fine-grained access control to source-aligned data. It really depends on requirements and technology used if such a layer makes sense so I put it here simply for inspiration.
- Granular business history: Data modelled for business use providing a harmonized, integrated view of the business at the lowest possible grain. This layer is commonly modelled dimensionally (Star Schema) or even as a Business (Data) Vault. As data is stored long term it has the history suffix.
- Business semantics: A (logic-only) layer managing business rules, measures, and metrics. This facilitates the DRY principle and can be regarded as the API of your data for analysts, BI tools, and AI agents. It defines the dimensions and metrics available, how they behave, and how they can be combined. This is a bit of the ‘new kid on the block’ but I believe it to be very valuable and here to stay so included it in this example. Technically this could be Databricks Metric Views, Snowflake Semantic Views or dbt Semantic layer.
- Business products: a layer holding specific business datasets like Data Marts. These are specific to use cases and often have limited history and are aggregated to a higher grain (like ‘daily sales per region’).
- Business products serving/caching: Additional layers can be added as needed—for example, a high-speed serving layer to fulfill specific low-latency requirements.
As shown it does not matter how many layers an architecture has and remains possible to insert a layer at a later point without creating awkward names. The principles behind the medallion architecture still remain as they totally make sense (and existed even before the medallion madness was defined).
Conclusion
As Piethein Strengholt highlights, layers must have clear responsibilities that fulfil specific requirements. Thinking in terms of Source vs. Business, Logic vs. Data and Stage vs History is not a silver bullet, but it provides a stronger data foundation than a set of metals. Although the example is primarily intended to show the guideline I do believe most of these layers are very common and make sense to have. The set up would then look like something like the following:
Raw source stage (landing) ➜ Tabular source history (bronze) ➜ Tabular Source History (silver) ➜ Business History (gold) ➜ Business Products (platinum)
In my recent projects, I have found that when people are “liberated” from the three-layer default, they start thinking more critically about the actual responsibilities of their data layers. The result is consistently more fruitful discussions and a more resilient architecture. I really hope people find it useful or even improve upon it as they feel fit.



