
Much of today’s innovation spotlight is on Large Language Models and Generative AI, but specialized AI techniques have been improving rapidly and often more quietly in the background. This article highlights how advances in areas such as computer vision and pattern recognition are delivering significant, practical impact across industries. Especially because the world produces far more visual and sensory data than text, progress in these fields has an outsized effect on how organizations can understand, automate, and optimize real-world processes.
Recently, the Data & AI team of Eraneos held its bi-annual Innovation Day, where we explore cutting edge tools and techniques chosen by popular demand. One of the teams chose to search for real-world applications using META’s newest pre-trained computer vision model – Dinov3. After testing several use cases, the team built a demo highlighting the way specialized AI still holds immense value – especially in performing a variety of powerful computer vision tasks quickly, cheaply, and without the need for large amounts of labelled data.
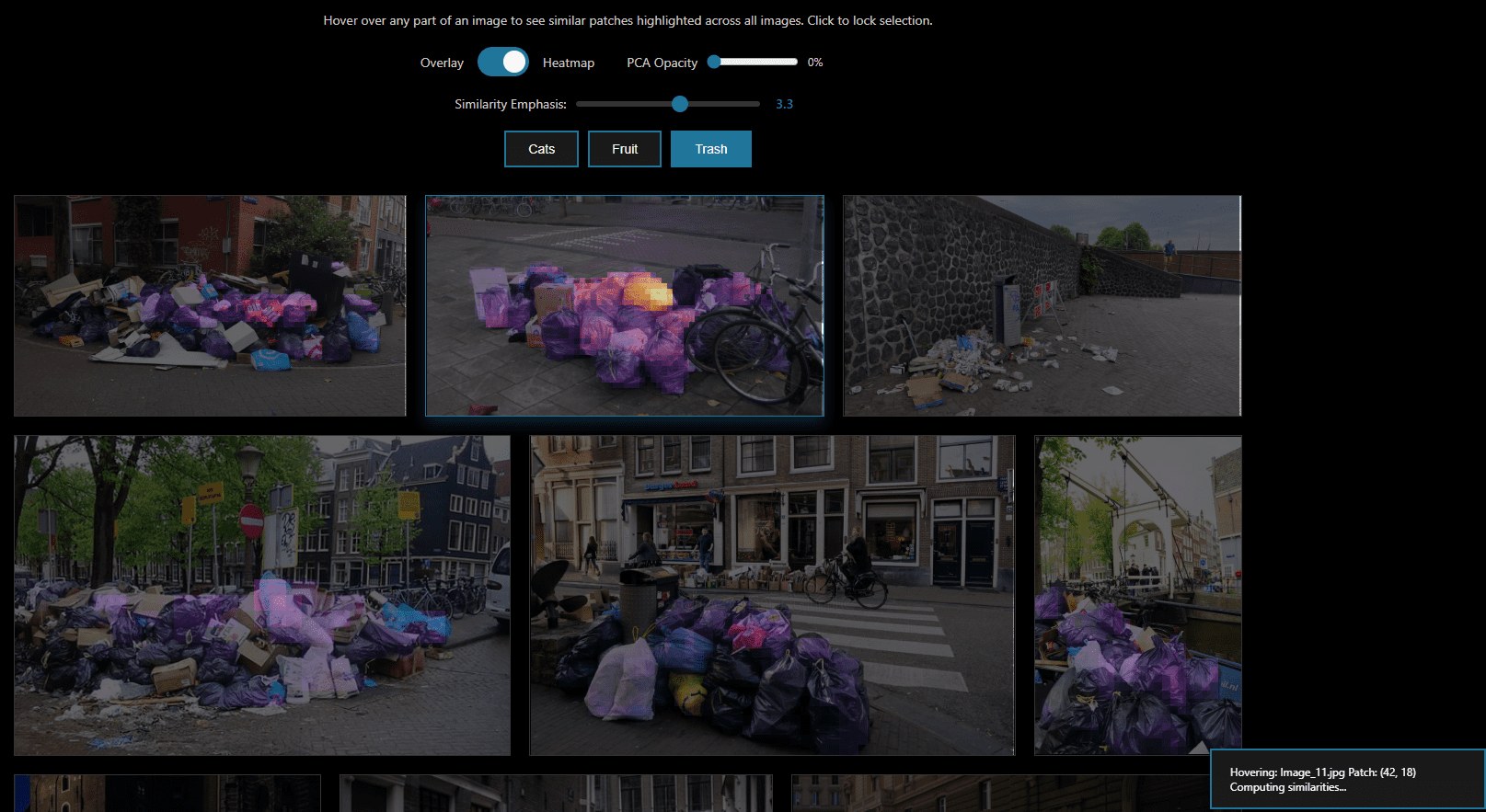
Image generated with the Eraneos DINOv3 Patch Similarity Viewer
The project team, composed of both data scientists and software data engineers, collaborated to align on the model’s capabilities and how they could be best applied. We structured the day to not only understand this classic AI technology but to rapidly demonstrate its extensive potential through multiple use cases, centered around a practical and relatable subject: trash detection.
Motivation
The team was drawn to Dinov3 because it is a dedicated computer vision model and not a standard generative one. Unlike most GenAI models, Dinov3 solves specific, real-world problems with unprecedented efficiency. The model’s USP lies in its training: it was not trained using any human-labelled data, but rather on billions of unlabelled images. This self-supervised learning process makes the resulting image representations, known as vector embeddings, incredibly rich and powerful. This training process addresses the single biggest bottleneck in traditional computer vision projects: the time and cost required to manually label vast datasets. Moreover, the model has smaller versions which are able to run on edgeware and in real time, and it can be used for a variety of tasks with minimal effort, as we demonstrate further below.
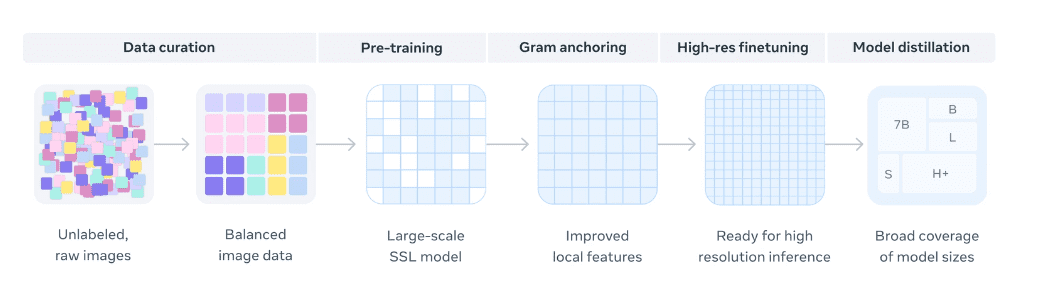
DINOv3 Data curation
The Meta team used a technique where the Dinov3 model was trained on a massive, unlabelled dataset of images to figure out structure and meaning by itself, similar to how a LLM learns language structure by reading the entire internet. The Dinov3 model works in a fundamentally different way from other AI models, including Meta’s Segment Anything Model (SAM), which, while advanced, is likely to still have required substantial labelling during its training phase. In using Dinov3 for our use cases, the team aimed to prove that advanced computer vision is now easily and cheaply accessible to virtually any physical industry.
Rethinking waste management
The public sector still relies heavily on manual processes for monitoring, inspection, and enforcement, particularly in areas such as waste management and public space maintenance. Detecting illegal dumping, littering, and hazardous waste remains labor-intensive and costly for municipalities, yet it is well suited for automation using modern computer vision. For this reason, during the Innovation Day we chose garbage detection as our application area, building on the team’s prior experience with municipal use cases.
The technical core of our work was based on the output of the DINOv3 model. Each image is decomposed into 16×16 pixel patches, with the model generating a rich vector embedding for each patch that captures both semantic meaning and geometric structure. These embeddings form the foundation for all downstream tasks, such as similarity search, classification, segmentation, and tracking.
Over the course of the day, we built and demonstrated four distinct applications that illustrated the versatility of this approach.
Visual semantic similarity – Finds all similar objects across a dataset without fine-tuning
In one web demo, selecting a single patch, for example a piece of trash, immediately retrieved and highlighted all similar objects across the dataset, showcasing zero-shot segmentation.

Image generated with the DINOv3 Patch Similarity Viewer
Here, it is Important to note that the visual semantic similarity detection works out of the box without fine-tuning, retraining or changing the frozen model in any way. Imagine if you could select one object in an image and be able to instantly find all similar objects in your entire image (or video) dataset without time and capital intensive labelling and training cycles for custom visual models.
The potential use cases are endless, however, we’ve outlined a few applications of finding all similar objects across a dataset without fine-tuning:
- Retail inventory management – Instantly identify all instances of a specific product across warehouse images for stock counting
- Duplicate report detection – Compare citizen-submitted images of issues (potholes, graffiti, trash) to identify duplicate reports for municipalities
- Quality control in manufacturing – Select a defect type once, then automatically flag all similar defects across production line imagery
- E-commerce product matching – Find duplicate or similar listings across large catalogs to prevent fraud and improve search
- Wildlife conservation monitoring – Identify all instances of a specific animal species across camera trap footage without species-specific training
Video object tracking – Follows a selected object reliably throughout a video sequence
In another example, the model was used for object tracking. How this works is once an object was selected in a single video frame, it could be reliably followed throughout the remainder of the sequence.
Image generated with the DINOv3 Patch Similarity Viewer
Here, we’ve also outlined a few potential applications of following a selected object reliably throughout a video sequence:
- Logistics and warehouse automation – Track packages, pallets, or forklifts through facility cameras to optimize flow and detect bottlenecks
- Sports analytics – Follow individual players or the ball throughout a match for performance analysis and tactical insights
- Traffic monitoring – Track vehicles through intersections to analyze traffic patterns, detect violations, or measure congestion
- Retail customer journey analysis – Follow shopping carts or customers through stores to understand behavior and optimize layouts
- Construction site safety monitoring – Track workers and equipment to ensure compliance with safety zones and protocols
Object detection – Classification with minimal labelled examples
We also trained a lightweight classification model using only around 20 examples to identify dangerous objects such as laughing gas cylinders and broken glass. Despite the minimal training data, the model achieved strong performance with 80% accuracy on broken glass detection and 100% accuracy on laughing gast cylinder detection. This highlights how powerful embeddings enable rapid model development.
With DINOv3 it is now possible to do custom object detection using an order of magnitude less labeled training data. This significantly reduces the costs and thus many applications that were previously too expensive to implement have now become feasible.
A few applications of lightweight classification with minimal labeled examples (~20 samples):
- Hazardous waste identification – Detect dangerous items like chemical containers, needles, or gas cylinders in public spaces or waste streams
- Infrastructure defect detection – Identify cracks, corrosion, or damage on bridges, roads, and buildings with minimal training images
- Agricultural pest and disease spotting – Train quickly on a few examples of crop disease or pest damage for early detection
- Counterfeit product identification – Detect fake or non-compliant products on assembly lines or in customs inspections
- Safety equipment compliance – Verify workers are wearing required PPE (helmets, vests, goggles) in industrial environments
Segmentation – Unsupervised clustering into meaningful categories
Finally, through unsupervised clustering, the system was able to group image patches into meaningful categories such as “garbage,” “water,” and “vegetation” without any predefined labels, demonstrating its ability to structure visual data automatically. A human only has to label a category once for it to be recognizable across the entire dataset.

Image generated with the DINOv3 Patch Similarity Viewer
A few applications of unsupervised clustering into meaningful categories:
- Land use and urban planning – Automatically categorize satellite or aerial imagery into zones (vegetation, water, buildings, roads) without predefined labels
- Environmental monitoring – Segment drone footage to quantify areas affected by flooding, deforestation, or pollution
- Medical imaging triage – Group tissue regions in pathology slides or scans to highlight areas requiring closer inspection
- Agricultural field analysis – Segment crop imagery to distinguish healthy vegetation, stressed areas, weeds, and bare soil
- Autonomous vehicle scene understanding – Categorize road scenes into drivable surfaces, obstacles, pedestrians, and signage for navigation systems
What we achieved
In just one day, our team was able to demonstrate that Dinov3 is a tool of extraordinary scope. We confirmed its capability to deliver high-performance results across various critical computer vision tasks – identification, counting, tracking, and segmentation – with minimal data or manual input.
The applications are extremely broad, reaching any industry that uses human oversight or cameras to assess physical reality, from municipal trash collection (detecting duplicate reports by comparing images) to manufacturing (quality control and component tracking) and retail (inventory management).
Perhaps the most significant achievement is the proof of concept for a full-package solution. The vector outputs from Dinov3 can be seamlessly integrated with our existing data deduplication and matching solution, Data Unity, which uses libraries such as Splink under the hood. Where we previously applied vector embeddings derived from text alongside structured data for entity matching, we can now extend this approach to visual data as well. This enables the creation of robust systems that compare images, text, and metadata simultaneously, significantly improving the reliability of duplicate detection and data quality processes. Through our experiments with DINOv3, we demonstrated that these capabilities can now be delivered faster, more cost-effectively, and more comprehensively than before.
The way forward
The outcomes of the Innovation Day clearly demonstrate how far computer vision has advanced in recent years. The technology can now recognize, classify, and group visual information quickly, accurately, and at scale, significantly reducing the manual effort required to review and interpret images. This opens up a wide range of practical applications across the public sector, manufacturing, retail, packaging, and any other domain where visual data plays a role.
Want to find out more about the Eraneos DINOv3 Patch Similarity Viewer built by our team and the benefits of applying the technology to your operations? Get in touch with us today to find out more.




