
Why is accuracy a poor metric of performance and how to reduce bias?
In this article we touch on a very important topic for many businesses that are starting on their data activation journey – the (un)importance of Accuracy in models. Because it is something we see frequently, we wanted to talk a bit more about why accuracy is a poor metric to base your machine learning models on and how you can actually reduce bias by introducing Precision and Recall in pattern recognition.
Often times, when companies want to do something with their data they talk about accuracy: “How do I get the most accurate model?”, is a common question we get. But usually a more important question is: “What are you trying to achieve or what problem are you trying to solve?”. And in most cases, accuracy can only get you halfway there. Let’s look at two common examples where accuracy is a terrible predictor for performance:
Case 1
A manufacturing client works with machines that need periodical maintenance. Ideally, this maintenance can be predicted well in advance in order to avoid machine downtime. They approached us to build a predictive maintenance solution that can solve that problem.
Based on a huge data set we built and tested several models. The biggest challenge was working with a data set that has thousands of cases where the machine was working perfectly and only several when it was failing. This is a common classification issue of having unbalanced data, where you have unequal instances for different classes. If 99% of your data set is “non-failure”, then you can always predict non-failure and get 99% accuracy rate. But you haven’t learned anything. You still can’t predict when the machine will break.
In this case, striving for Accuracy will give you a faulty model. In order to understand the issues, we first need to see how a typical IoT architecture looks like.
Case 2
Let’s say we have the following confusion matrix, which shows that the algorithm we’ve built has an extremely high accuracy rate with 998 accurately predicted negative cases and only one positive which slipped through.
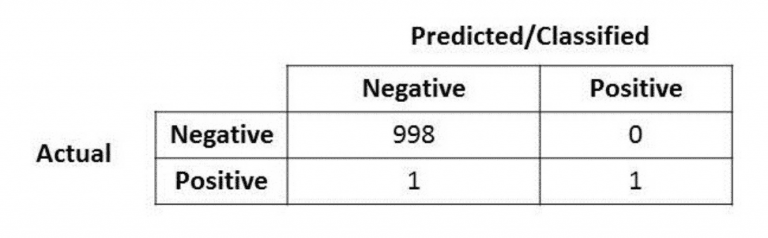
Generally, you’d be very happy with a result like this, if it’s a lead list and you are cold-calling people for a new product or service. But what if the missed positive represents a dying patient that should have received an operation, or in a grim extreme, a terrorist that wasn’t caught? In some cases, the costs of having a mis-classified value can be very high. And in those cases, Accuracy is not enough. This is where Precision and Recall come in.
The alternative
While Accuracy is simply the ratio of correct predictions over all predictions, the other two are a bit more complex but very intuitive if you look at them in the context of our examples.
Recall
Recall is the ability of a model to find all the relevant cases within a data set. So, looking back to the 2nd example, if we really want to find that extreme case which slipped through, we will have to optimize our model for a high recall ratio.
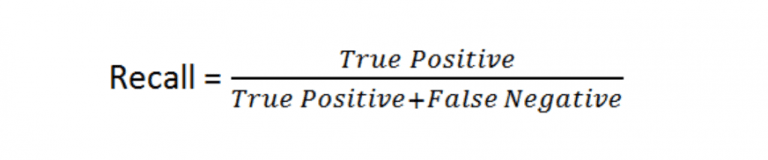
As you can see from the definition, Recall is simply the ratio of true positives (classified as positives and are positives) to true positives plus false negatives (classified as negatives but are actually positives).
So far so good. But if Recall shows us which values are significant in a data set, can’t we just focus on that and call it a day? Well, no. Using the same example, if we just optimize for Recall and classify all the values as “positives” we will get all the important data points but because they are so few, everything else will be wrong and the accuracy will plummet. Which means we still haven’t learnt anything.
Precision
Here is where Precision comes in. If your model has a very high recall but low accuracy, then it’s most likely suffering from lack of Precision, which is the ability of the model to identify which of the classified as relevant data points are actually relevant.

Precision is the ratio of true positives to true positives plus false positives (labeled as positives but are actually negatives).
Most businesses will optimize for either Precision or Recall, but it’s worth mentioning that you can combine the two into a measurement called the F1 score, which is good to know but not necessary for this article.
The bottom line
As you can see, Accuracy is a good metric of performance only if the costs or consequences associated with missing a false positive or a false negative are very low. Often, to fully evaluate the effectiveness of a model, you need to examine both Precision and Recall. It’s good to remember though, that those two metrics are at odds and improving one usually reduces the other. Like the knobs of your sink, you can adjust them until you find the right balance, depending on what the business goals are.
If there is one thing that you take out of this brief explanation, remember that we tend to choose accuracy because everyone knows what it means, not because it is the best metric for the job. Usually, there are better options which might look confusing at first glance but are actually very intuitive and more useful.
These two metrics are more than just mathematical constructs, in fact, their understanding is crucial for any organization that wants to squeeze out the most business value out of their A.I. journey. Knowing about Precision and Recall can help you not only to set better business goals but also reduce any pre-existing biases that may be lurking in your models!



