The Databricks Power BI task, available in Databricks Workflows, is more than just a model refresh tool. It’s a powerful and surprisingly elegant solution for automated schema evolution. It can automatically propagate schema changes from your Databricks Unity Catalog to your Power BI semantic models, including new tables and columns, while preserving your existing Power BI artifacts like measures and relationships. It works very well when adding things to the model but deleting things is a different story…
Introduction: A task that does more
As data and data engineers, we’re constantly looking for ways to automate our pipelines. The journey from raw data to a user-facing models and reports in Power BI is a common challenge. The typical solution for ensuring reports are up-to-date involves scheduling model refreshes which in practice can be to early (data processing not done yet) or to late. Updating models, for example adding columns or entire tables with their relations, often requires a manual update and publish of the model by a Power BI engineer.
When I first came across the Databricks Power BI task in Databricks Workflows, I assumed it could only trigger model refreshes. This is helpful to avoid the timing issues described above but to my surprise the Power BI Task is far more sophisticated. It is not just a trigger; it also maintains the semantic model and can automatically sync data changes such as additional columns, tables and relationships. This ability to automatically propagate these changes to the semantic model without the need for a Power BI expert is extremely helpful for maintaining business datasets.
A trial in practice
To fully understand its capabilities, I configured a Databricks Workflow with a Power BI task. The objective was to manage a semantic model in Power BI based on a dimensional model in a Unity Catalog schema.
I started by creating a Unity Catalog schema for my semantic model and added a dimension and a fact table, including a foreign key constraint between them. When the model is published to Power BI, these constraints are used as relationships between the tables. It must be noted that Databricks does not support such constraints on views, which makes sense given their traditional purpose. But in this context, where they are simply used to inform about relationships, it is a limitation. Not only for Power BI but also for users who want to understand a data model.
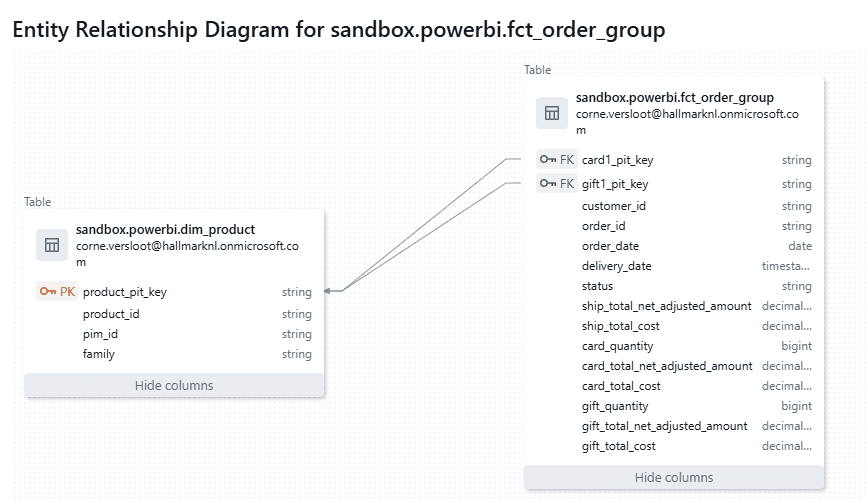
The entity relation model for this experiment as present in Databricks is shown below. It actually has two relations to the same dimension table which is not supported in Power BI.
The final step needed is to configure and run the Power BI task. I configured it using my schema as the source to update to Power BI. This means that any tables and views in this schema, including any changes to them over time, will be propagated to Power BI.

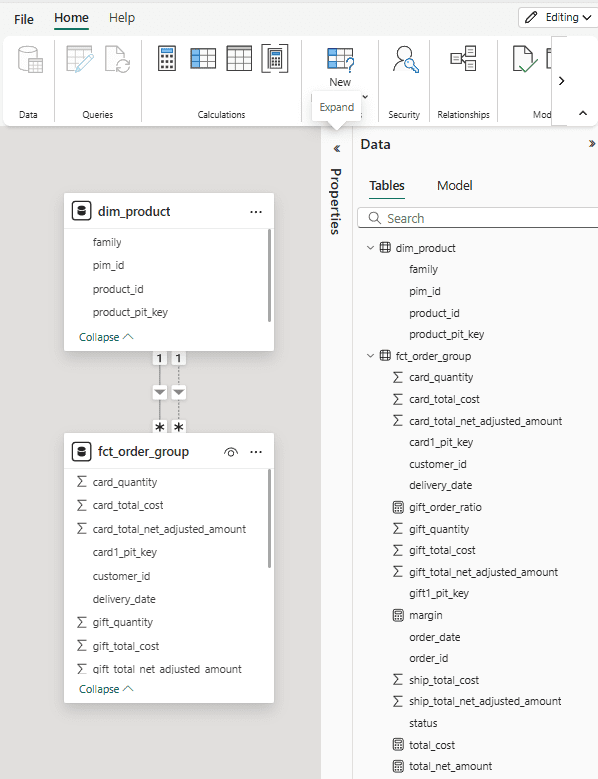
The semantic model in Power BI is shown here and contains the tables and relations as they are present in Databricks. It must be noted that one of the relations between the fact and dimension table is set to be ‘inactive’ as Power BI supports only one relation between any two tables. I added some measures to the model because I wanted to know if these would remain after I ran the Power BI task again.
After this initial step, I made some changes to the Unity Catalog schema in Databricks and added:
- Some columns to the existing tables
- Two more dimension tables, including their relations to the fact table
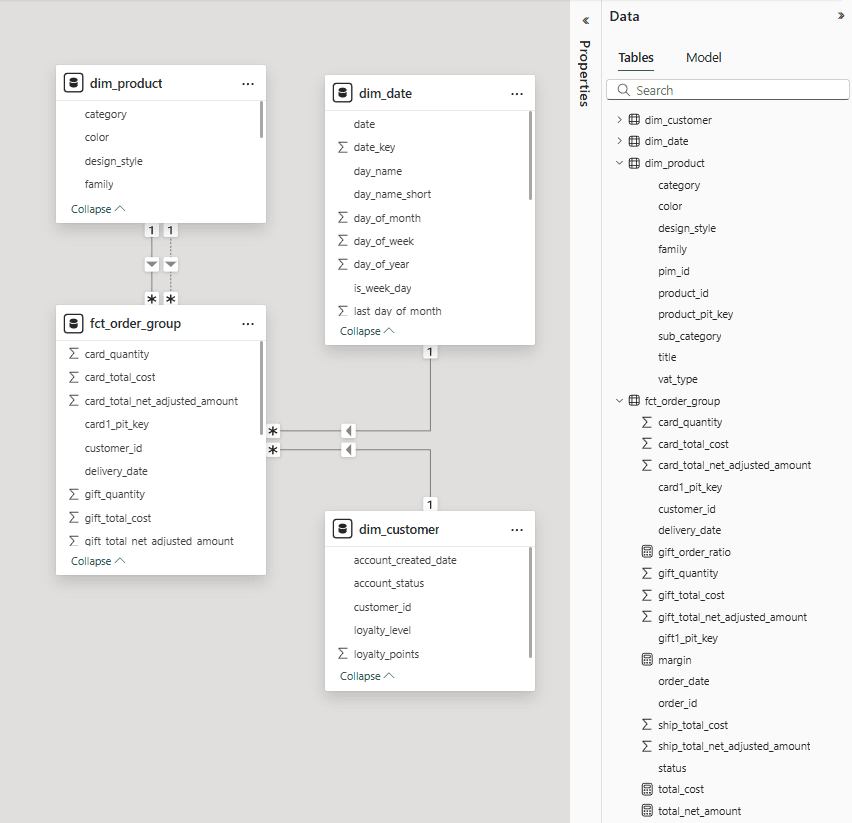
The result in Power BI after running the task again is shown below. All changes are propagated to the semantic model, and the measures I put there still exist.
Next, I removed all relations between the tables in Databricks and published the model again. I expected the relations in Power BI to vanish as a result but was positively surprised this was not the case. All relations and measures were still there, showing the incremental nature of Databricks Power BI task. This helps protect the model against accidental removal of such relations but also means manual cleanup if they really have to go.
Finally, I deleted columns and one of the tables within Databricks which resulted in failed refreshes. It did not matter if a table or column was used by a measure or link; any deletion resulted in failure. This does make sense as it protects the model and all related models and reports from unwanted deletions. But the question now is how to actually delete things that really can go… I was unable to do this in the Power BI web editor and all searches on this topic basically tell me I need to ‘manually’ remove what I want using the XMLA endpoint. For sure it can be done but is currently beyond my (honestly limited) Power BI capabilities.
To conclude
The Databricks Power BI task is a powerful tool for any modern data stack that leverages both Databricks and Power BI. It’s a significant step toward a more unified and automated analytics workflow, freeing up engineers to focus on building new value rather than performing manual maintenance. For now the changes can only be incremental it seems which really is a disadvantage to consider.



