
We started using Databricks Delta Live Tables (DLT) earlier this year when it became compatible with Unity Catalog. We felt it was mature enough to start using it for real, and in this post I will share our experiences so far using it for batch processing.
DLT is Databricks’ own optimized transformation framework that works with both streaming and batch data. It’s very convenient because it automatically tracks data that hasn’t been loaded yet and does all the task orchestration for you. All you need to do is define the transformations from your input tables to your output tables, and DLT will figure out the dependencies and execution order.
You can do this using SQL with simple CREATE TABLE AS SELECT (CTAS) statements. But frankly, DLT really shines when you use Python. It supports imperatively programmed pipelines, which means you can define and work with hundreds of tables by looping through configuration and/or staged dataset directories.
This introduction only scratches the surface, but there are plenty of resources to help you get started. Check out these links for more information:
Customer case
One of our e-commerce clients is in the midst of a major overhaul, moving most of their services to SaaS solutions like Salesforce. We stepped in to build their Lakehouse while their new e-commerce setup was still being put together. This meant that our data sources were constantly changing, with new tables and columns being added, updated, and removed on a daily basis. This is where DLT shines. It can automatically handle new tables and evolve schemas without any engineering, or at least very minimal engineering compared to a non-DLT approach. This article describes how we use DLT to minimize our engineering efforts.
Our setup
For this project, we are using a standard Azure setup:
- Azure Storage Accounts: These have a hierarchical namespace and hold both staged data and Unity Catalog managed tables
- Data Factory: Handles data loading and top-level orchestration like copying data around and starting Databricks DLT pipelines and Jobs
- Databricks: Manages everything else: permissions in Unity Catalog, data transformations using DLT and workflows, analytics with SQL, etc
- Other Services: We also use Key Vaults, Log Workspaces, Networking components, etc., but they are not the focus here
The data architecture and components used are outlined below.
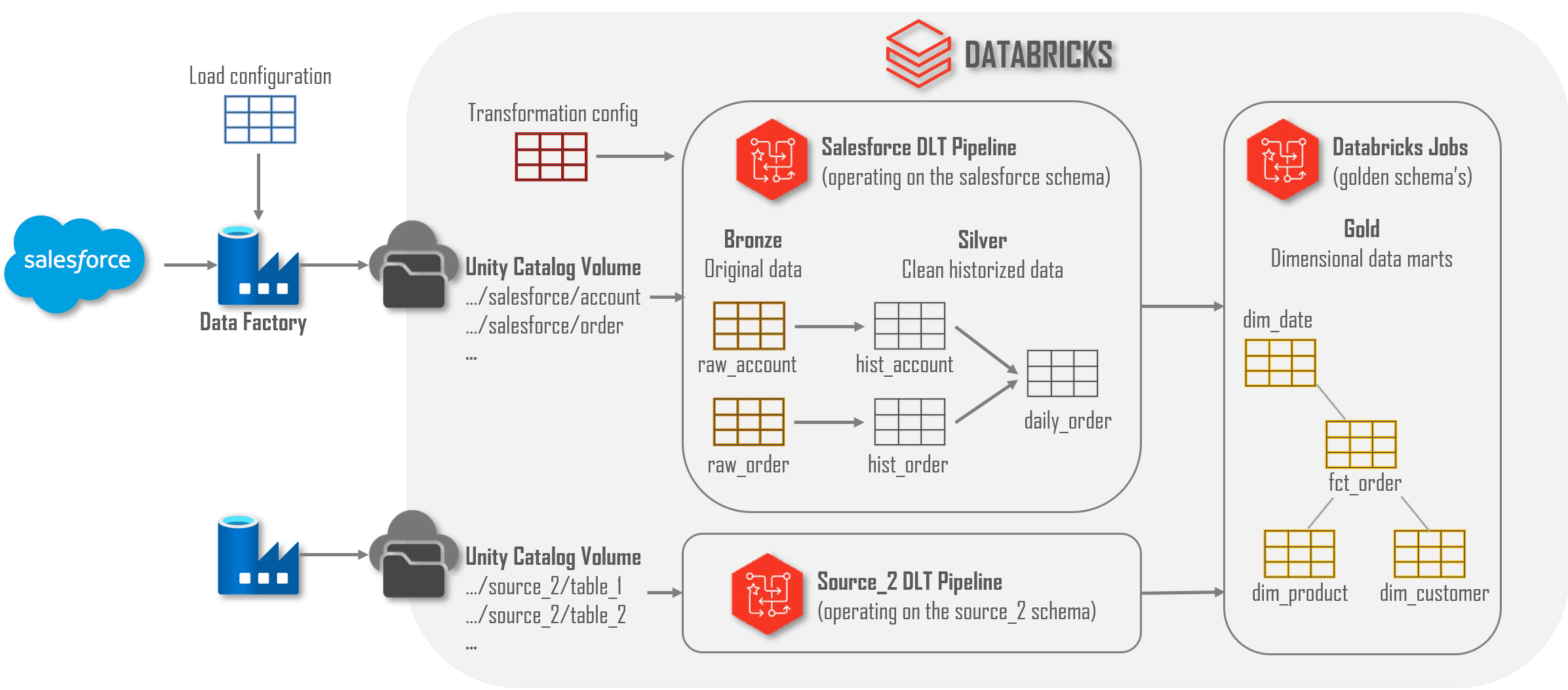
Here is a breakdown of our data architecture and components:
- Data Loading with Data Factory:
- Data Factory copies all source tables/datasets to a Databricks Volume based on its configuration. We manage source tables and columns within the configuration, not the code.
- All data copied by Data Factory is written to Datalake storage mapped to a Unity Catalog Volume.
- Creating Bronze and Silver Tables with DLT:
- A DLT pipeline creates bronze and silver tables for each directory it finds in a specific storage Volume location. So, when an additional source table is configured and copied by ADF, the DLT pipeline automatically picks it up and creates tables for it using schema evolution.
- Additional configuration within the DLT pipeline handles specific transformations, mostly for PII data (we will cover this in another article).
- Creating Golden Datasets with Databricks:
- Databricks jobs create golden datasets, which are mostly tabular data marts. Columns from (pre-aggregated) silver tables are integrated into facts and dimensions using business terminology rather than source system-specific names.
- While the bronze and silver layers are somewhat ungoverned (we load what we get), the golden layer is strictly governed to ensure high-quality data for consumers. Most of the golden layer objects are SQL VIEWS, which are easy to maintain and do not require reloading upon changes. If performance or costs become an issue, we might materialize those golden tables, but for now, we prefer the flexibility provided by views.
To be specific, I will describe how we load Salesforce data, but that is just one of the sources we have. All sources are loaded using the same patterns, although the transformations we use to cleanse the data typically vary by source or even by table.
Data Factory
The Salesforce data is copied to the data lake by Data Factory. The pipeline responsible for Salesforce first loads the configuration it needs using a LookUp action. Each record in this configuration contains all information needed to copy the delta of a single Salesforce object and includes: the object name, columns to include, target directory in the lake and the timestamp the object was loaded last.
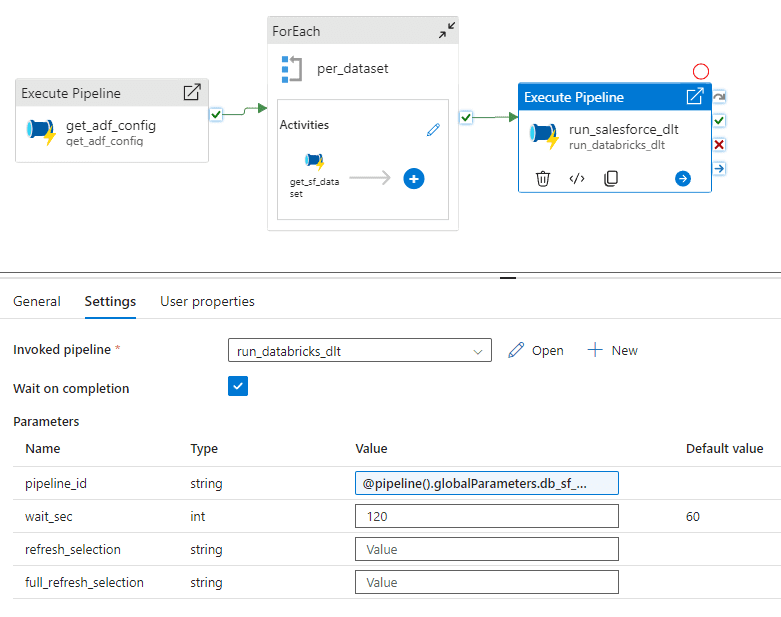
Adding an object to the Lakehouse (bronze and silver tables) only requires us to add a record to this metadata table with a last load timestamp of 2000-01-01 to make sure we get all records. Changing an existing table, for example adding or removing columns we want to copy, is done in the same way. Every time this pipeline runs it copies the new data for each configured object to the Datalake into a path like ecom-raw/salesforce//_load_ts=yyyy-MM-ddT… (partitioned on load timestamp). Once all objects have been copied, Data Factory starts the DLT pipeline. We created ADF pipelines to orchestrate Databricks DLT pipelines and jobs which leverage Databricks API to do this.
The entire ADF pipeline to load Salesforce data is shown below.
DLT Pipeline
Our DLT pipelines are set up to load all tables for a single source into the bronze and silver layers. This means each source has its own schema within Unity Catalog where the DLT pipeline operates. While this setup is clear and organized, it does have the drawback of not allowing us to perform transformations across different source systems (i.e., data integration). So far, this has not been a major issue, but I can foresee situations where we might need to load and combine multiple source systems within a single DLT pipeline (and thus schema) in the future.
The pipeline kicks off by listing all directories within the ecom-raw/salesforce/ location in the Datalake. For each directory it finds, a set of streaming tables is created. The screenshot below shows the main logic used to create the raw and historical tables. More details are provided in the following sections.
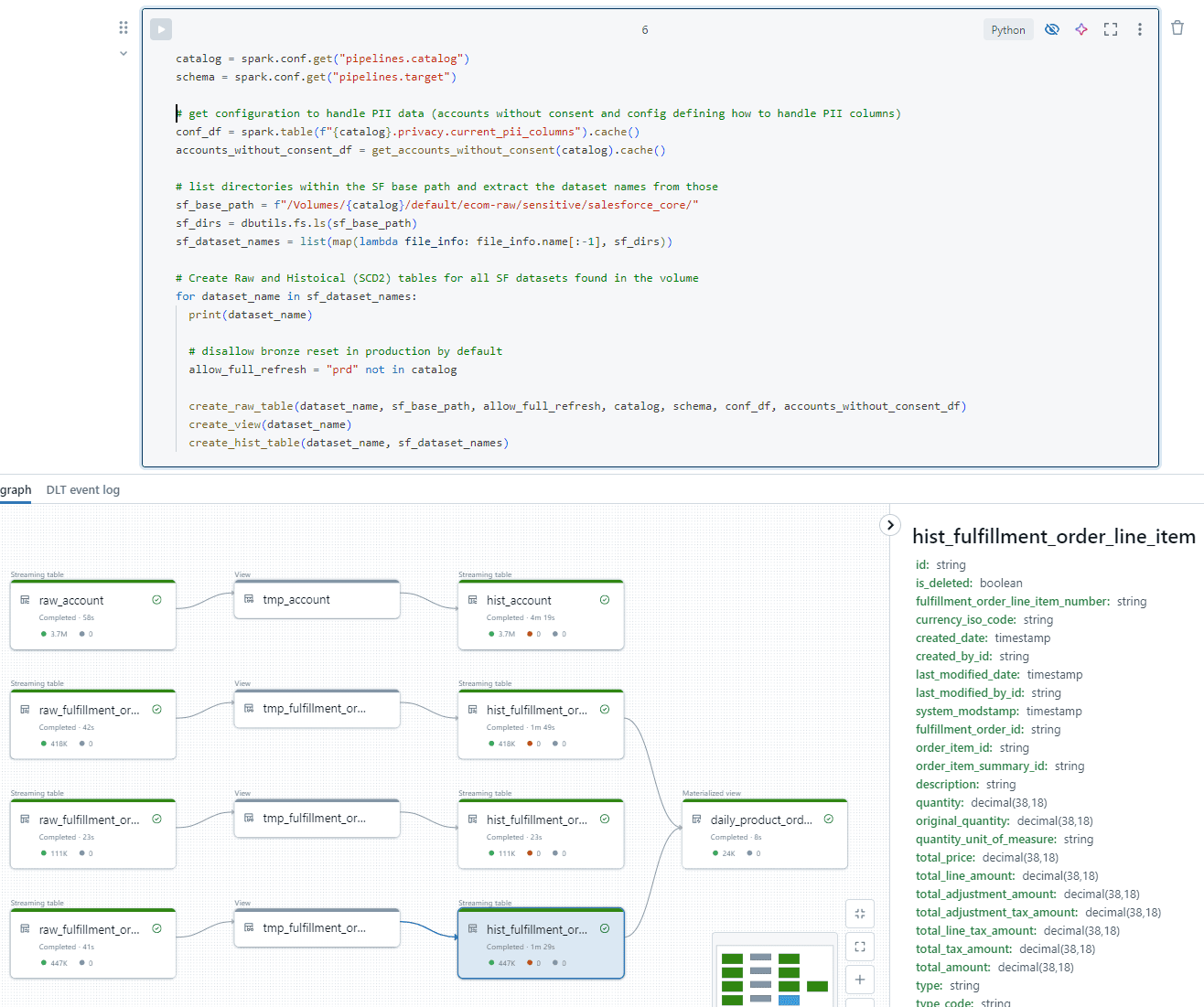
For each directory it will create the following objects:
- A bronze ‘raw_’ table using autoloader This link opens in a new tabconfigured to allow for schema evolution and using the _load_ts partition. These tables have the schema of the source and apply schema changes which are not breaking. As a result, it is possible to add and remove Salesforce tables and columns we want in Data Factory which are automatically handled by the DLT pipeline. There is no need to create the tables first, which makes it easier to manage.
- We maintain most of the code in separate Python modules and use these throughout the DLT pipeline. The notebooks mainly contain the @dlt code required by DLT, but no transformation logic.
- By default, we do not alter the data while loading it into bronze tables, except for one case related to privacy and PII fields. We maintain a configuration table that lists all PII fields and specifies what to do with them (nullify, mask, encrypt, etc.). This metadata framework is applied in the bronze layer and will be detailed in another article.
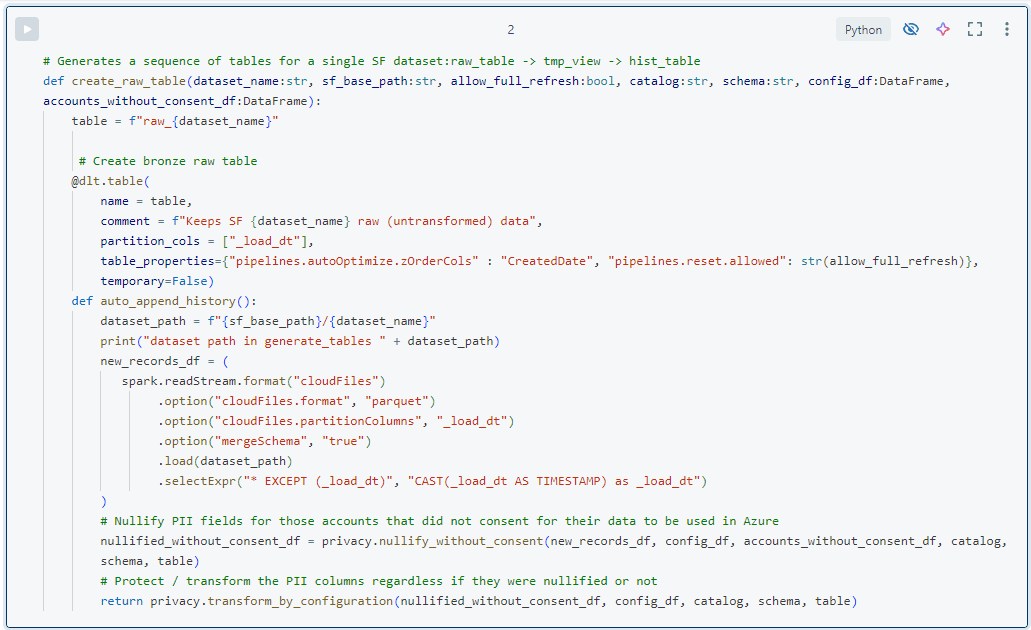
- The bronze table feeds into a ‘tmp_’ DLT view where we apply any necessary cleanup transformations. For Salesforce, this is usually minimal, but for other source systems that provide nested data, we flatten it or perform other cleansing operations to make the data easier to use. This view exists only within the DLT pipeline and helps manage complex transformations by breaking them into separate steps. In this view, we might include data quality checks to prevent faulty data from being loaded into the silver layer. A typical example is a NULL check on ‘rescued_data’, which indicates a schema conflict. Generally, we take a liberal approach to data quality and do not block records from being loaded unless we are certain something is wrong. While it is commonly understood that data quality should be defined by the producer, we find this can be too harsh. Why block records based on one column that might not even be used by any consumers?
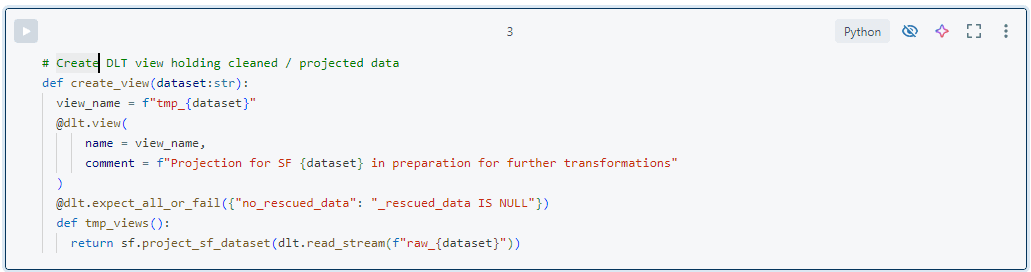
- The target silver table is used for historization of clean data and modelled as a slowly changing dimension type 2 (SCD2) in ‘hist_’ tables. Effectively this means that each record gets a __START_AT and __END_AT column indicating when it was valid. All records with __END_AT IS NULL are those which are currently valid. The DLT apply changes function is used to maintain these tables. For this we need the business key and sequence columns which are very static in the Salesforce Core data. For other sources we maintain this information in metadata.
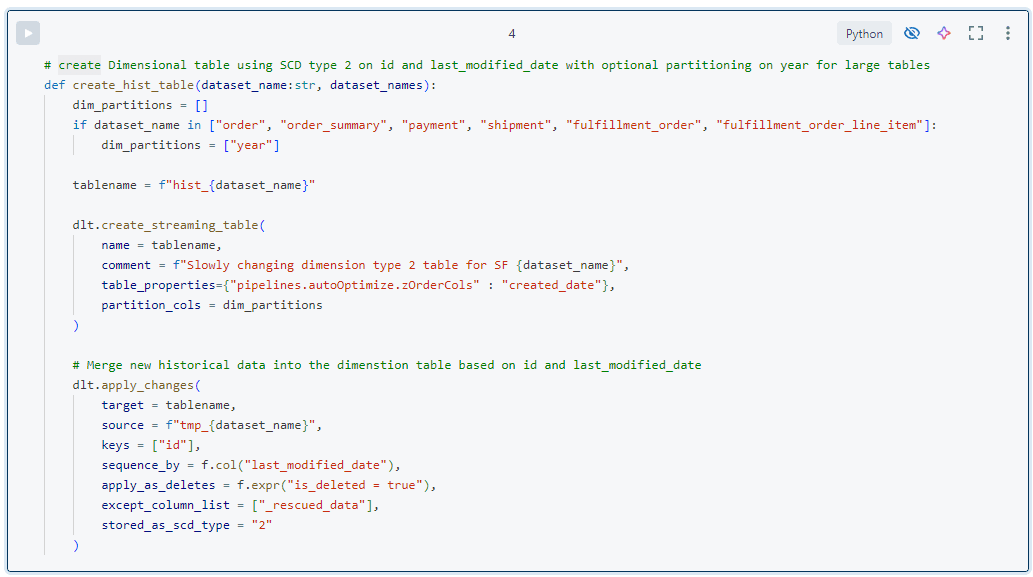
- Additional aggregation tables may be created within the silver layer by joining and aggregating other tables from the same source. The goal is to provide data which is easy to use for certain consumer groups like data scientists. An example is aggregation of fulfilled products per country per day. This type of table could be defined as gold but as we do not translate the data into business terminology we consider it silver.
Our setup has been solid. Changes in source tables are automatically picked up and historized in the silver layer, making it easy for consumers to access. Adding tables from existing sources is just a matter of configuration, no coding needed. Over the past few months, we have added dozens of tables based on business requests. While getting the required fields into the data marts does require some work and deployment, everything up to the silver layer is automated through configuration. This has significantly sped up our ability to deliver additional insights. DLT has served us very well so far, but that does not mean there are no drawbacks or interesting observations to share…
Observations and lessons learned
Overall, I think DLT is incredibly valuable, mainly because it uses automation and standardization to reduce the engineering burden and associated costs. Schema changes are handled automatically, and data changes, like nullifying PII fields, can be easily propagated using DLT. There is no need to manually perform UPDATE or DELETE statements on various tables – DLT takes care of it for you.
Since we use a lot of streaming tables instead of materialized views, operations in a bronze table require a full refresh of downstream tables. This can get expensive with large datasets, but so are the engineering hours needed to build jobs that do the same thing. We believe there are options to make this less costly, like consuming change feeds rather than the streaming table itself. Databricks is also working hard to optimize these scenarios with innovations like the enzyme engine and serverless compute This link opens in a new tab.
Developing and testing DLTs has become easier this year because Databricks integrated the notebook view with the DLT view. Now, you can run DLT pipelines and inspect their execution graph while working on the code. Although handy there are some drawbacks like the inability to see any printed debugging information. In my experience it is best to start developing using ‘normal compute’ and debug all functions before starting the DLT work in ‘DLT mode’.
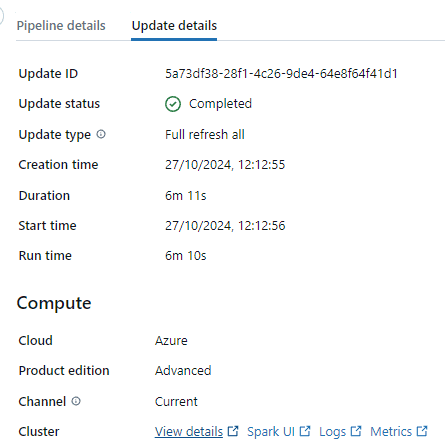
For development, the DLT configuration allows the cluster to be in ‘Develop’ mode, meaning it doesn’t terminate after a DLT run (unlike in Production mode). This is great for development, but the auto shutdown time is two hours or something, so every run you start will cost you two extra hours of ‘non-use’ of the cluster. As far as I know, you cannot change this auto shutdown time. However, you can find the cluster DLT uses in the ‘Update details’ section of the DLT view and manually terminate it to save costs (see screenshot below). This is something everyone should do, but Databricks does not make it easy. Another way to avoid this issue is to use Serverless Compute This link opens in a new tab which in my experience does ‘shut down’ rather quickly (and is fast to start up as well).
One thing few people know is that DLT pipelines ‘claim’ the tables they create. This means certain operations, like restoring a historic version, are not possible on DLT tables. Also, you cannot have multiple DLT pipelines working on the same tables. While this makes sense, it can cause issues when multiple people are working on the same pipelines. You cannot just ‘clone’ a pipeline to experiment. To work around this, each developer can have their own dev database and schemas for DLT, or alternatively, work on the same DLT pipeline at different times. Regardless of the approach, it is important to manage permissions on the pipeline to allow others to work on it.
Schema evolution is a fantastic feature, but its behavior in DLT can be a bit odd. Whenever a DLT run detects one or more schema changes, it will cancel its run, terminate its cluster, and start a new run to perform the schema update. The first time I encountered these ‘cancelled’ runs, I was really puzzled, but there are log entries that explain what is happening. One of our sources produces lots of small JSON files (thousands per day) that frequently change their schema. Because the JSON schema inference only looks at 1,000 files by default, we have seen cases where the pipeline restarted multiple times in a row to handle the changes. Thankfully, there is an option to change this default which is ‘spark.databricks.cloudFiles.schemaInference.sampleSize.numFiles This link opens in a new tab’.
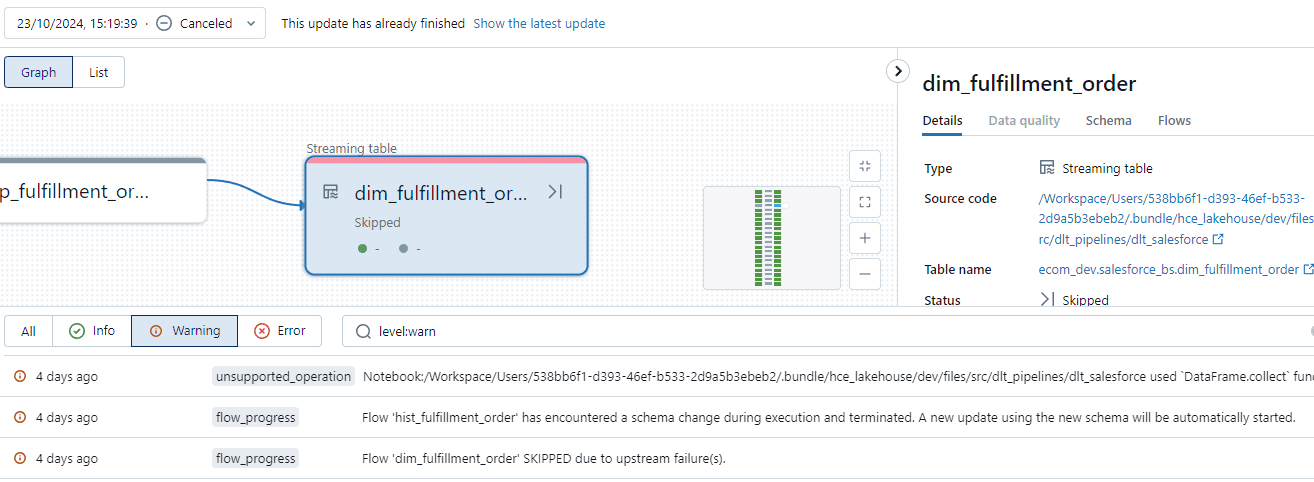
Another important point is that DLT can be quite demanding on the driver, especially when dealing with lots of tables and files. This can lead to terribly slow DLT pipelines due to garbage collection issues, which are clearly indicated in the logs (see below). Essentially, the driver needs more memory. Typically, we would use small drivers and larger worker nodes, but with the increasing complexity in query optimization and DLT planning, this is changing. So, make sure the driver is big enough to quickly set its executors to work. Skimping on the driver can actually cost you more in the long run, as the job can take significantly longer than it should.

A final note about the autoloader. It keeps track of all the files it has loaded and does not take into account the modification date of the files. So if you overwrite an existing file with something new, it will have no effect on the DLT because it will assume that it has already loaded the file and will ignore it. This can be quite confusing if you put some new data into storage and end up with nothing new in Databricks. So for new files, make sure you change something in the filename/directory to make sure it gets loaded.
That’s all I have to share for now, but stay tuned! We’re planning more articles to dive into how we use Databricks asset bundles for deployment and to provide more details on our privacy framework, including how we protect PII columns, handle consent, and manage the right to be forgotten. If you need help with any of these, or have other questions in the future, feel free to reach out. Happy Data Engineering!



